
 界智通
界智通 Claude Opus 4.8 全面解析:核心能力、成本优化与 获取API Key 开发实战
 jieagi_Pan
jieagi_Pan 执行摘要
截至 2026 年 5 月 29 日 的公开资料,Claude Opus 4.8 是 Anthropic 在官方文档中标注的“最强、且已正式可用的通用模型”,定位是面向高难度编码、长程代理任务、知识工作与专业文档处理的旗舰模型;它默认提供 1M token 上下文窗口(Claude API、Bedrock、Vertex AI),最大输出 128k tokens,并支持 adaptive thinking、自适应 effort、prompt caching、Batch API、Files API、PDF、视觉、多种服务端/客户端工具。对开发者最重要的变化是:无须 long-context beta 头、默认 effort=high、支持会话中途 system 消息、较低的最小可缓存长度,以及非默认 temperature/top_p/top_k 会直接返回 400,这意味着 4.8 更像“高自治、高稳定”的工程模型,而不是传统“靠采样参数细调”的通用聊天模型。
如果你的目标是复杂编程代理、深度研究、多文档分析、长上下文审阅、强工具编排,Opus 4.8 值得作为首选;如果你的目标是更低成本、更高吞吐的生产问答/RAG/客服,Claude Sonnet 4.6 往往更均衡。若你当前已在 Opus 4.7 上运行,升级到 4.8 没有破坏性 API 变更,但应立即检查四件事:删掉非默认采样参数、显式评估 effort、用 streaming 处理长请求、把会话指令更新切换为“中途 system 消息 + prompt caching”。
就成本与性能而言,官方标准价已降到 $5/MTok 输入、$25/MTok 输出;Prompt Caching 命中价为基础输入价的 10%,Batch API 继续提供 50% 折扣,Fast mode 则把 Opus 4.8 提升到 $10/$50 per MTok 的更高单价以换取更快输出。官方没有给出统一的延迟/吞吐 SLA;第三方 Artificial Analysis 在“Adaptive Reasoning, Max Effort”的公开测量中显示,不同提供商上的 Opus 4.8 首 token 延迟约在 7.36s–20.02s,输出速度约 60.1–64.4 tokens/s,说明提供商选择会显著影响体感性能。

模型概述
官方定位。 Anthropic 将 Claude Opus 4.8 描述为其“most capable generally available model”,并强调它是对 Opus 4.7 的升级,重点提升了编码、agentic workflows、专业知识工作、协作体验与诚实性。官方发布页还明确写到,4.8 更倾向于主动标示不确定性,在内部评估中“约比前代少 4 倍”地让它自己写出的代码缺陷“悄悄通过而不提醒”。发布页与迁移指南共同表明:4.8 属于 Anthropic 当前旗舰开发模型,而非单纯聊天优化版本。
架构要点。 官方公开材料没有披露 4.8 的参数规模、层数、是否 MoE、训练 FLOPs 等底层架构细节;这部分应明确视为未指定。公开可确认的是:Claude 4 系列属于 hybrid reasoning large language models,支持标准响应模式与extended/adaptive thinking;4.8 延续 4.7 的能力面,支持 adaptive thinking,并通过 output_config.effort 调节思考深度。Anthropic 对 4.7 的透明度说明写到,该代模型经历了大规模预训练和以 Claude Constitution 为目标的后训练对齐,训练数据包括公开互联网信息、公共/私有数据集、以及其他模型生成的合成数据;这可以作为 4.8 的最近官方架构代理,但不能机械外推为 4.8 的完整训练细节。
能力边界与规格。 4.8 在 Anthropic 自家平台、Amazon Bedrock、Vertex AI 上默认提供 1M token 上下文窗口,在 Microsoft Foundry 上发布时为 200k;单次最大输出为 128k tokens。它支持 vision、PDF support、Files API、Batch processing、Prompt caching、服务端与客户端工具,并且从 4.8 开始,1M context 不再需要 beta header,也没有 long-context premium。同时,4.8 支持一个对工程非常有价值的新能力:你可以在 messages 数组中、用户消息之后插入 role: "system" 作为中途系统指令,以便更新行为约束而不重建整段前缀上下文、从而更容易保留 prompt cache 命中。
优点。 对开发者最直接的优势有四类。第一,长上下文与代理式执行:官方把 4.8 定位到长会话、长文档、长程代理工作流,并把 1M context 作为默认能力;第二,更强的工程可控性:中途 system 消息、prompt caching、batch、tooling 组合,使其更适合生产编排;第三,更好的“诚实性”和不确定性暴露,这对审计、高风险知识工作、代码复查尤其重要;第四,价格相较早期 Opus 4.x 显著下探,标准价从 Opus 4.1/4 的 $15/$75 降到 4.8 的 $5/$25。
限制。 4.8 也有几个非常关键的“坑点”。最重要的是,对该模型设置非默认 temperature、top_p 或 top_k 会 400;你应把“思考深度”交给 thinking={"type":"adaptive"} 与 output_config.effort,而不是继续走以前的采样调参思路。其次,prefill 在 Opus 4.8 上不支持;如果你过去用“assistant 预填充”控制输出起始格式,官方建议改用structured outputs 或系统提示。再次,长请求如果不用 streaming,官方 SDK 会认为它可能超时并直接报错或提前终止重试。最后,公开官方资料虽然反复提到 Claude Opus 4.8 System Card,但截至本报告撰写时,Anthropic 的公开 system cards 索引页尚未列出 4.8 条目;因此,4.8 的完整安全评估文档在公开可检索性上仍有不确定性。
API获取 与 SDK 调用示例
更快获取 Claude Opus 4.8 API Key:通过 uiuiAPI 统一接入
对于个人开发者和中小团队来说,想要体验 Claude Opus 4.8,第一步通常是准备可用的 API Key。不过在实际开发中,如果同时需要测试 Claude、GPT、Gemini、DeepSeek、Grok 等多个模型,逐个平台申请账号、管理密钥、适配不同接口格式,往往会增加不少额外成本。
这类场景下,可以考虑使用 uiuiAPI.com 这类聚合 API 服务。它将多种主流大模型统一到一个调用入口中,开发者只需要在后台获取一组 API Key,就可以通过相对统一的方式调用 Claude Opus 4.8 等模型。对于已经兼容 OpenAI 风格 /v1/chat/completions 接口的项目来说,接入成本通常比较低,只需要调整 base_url、api_key 和 model 参数,就能快速完成测试和迁移。
从开发体验来看,uiuiAPI 更适合用于模型选型、产品原型验证、AI 编程助手、知识库问答、自动化内容生成和 Agent 工作流等场景。开发者可以先用统一接口快速验证不同模型在回答质量、响应速度、成本和稳定性上的表现,再根据业务需求选择最合适的模型组合。
这种方式的价值并不只是“多一个 API Key 获取渠道”,而是让模型接入变得更灵活:简单任务可以使用轻量模型控制成本,复杂代码分析、长文档理解和多步骤推理任务则可以切换到 Claude Opus 4.8。对于需要快速落地 AI 应用的团队来说,统一入口、统一密钥管理和统一调用规范,能明显减少前期试错成本。
当然,如果项目对官方账单、合规体系或原生平台能力有强依赖,也可以直接接入 Anthropic 官方 API。更务实的做法是:早期通过 uiuiAPI 快速完成测试和业务验证,等产品形态稳定后,再根据调用规模、成本结构和合规要求,决定继续使用聚合接口,还是进一步接入官方 API。对开发者来说,最重要的不是拘泥于某一种接入方式,而是让模型调用更稳定、成本更可控、开发效率更高。

下面的示例以 Anthropic 官方 Claude API 为基准。核心原则只有两条:一是 Messages API 是无状态的,你需要自己保存并回传完整对话历史;二是 Opus 4.8 不要传非默认采样参数,重点改用 thinking 与 effort。
Python
# 场景:服务端应用 / Web API / 后台任务
# 覆盖:认证、会话管理、adaptive thinking、streaming、重试、上下文计数
import os
import asyncio
from anthropic import AsyncAnthropic, DefaultAioHttpClient
import anthropic
MODEL = "claude-opus-4-8"
client = AsyncAnthropic(
api_key=os.environ["ANTHROPIC_API_KEY"],
http_client=DefaultAioHttpClient(), # 更适合高并发 async 场景
max_retries=2, # 官方默认就是 2,这里显式声明
timeout=60.0 # 长请求建议显式设置
)
async def ask_claude(history, user_text):
messages = history + [{"role": "user", "content": user_text}]
# 先做 token 估算,避免 context overflow
token_est = await client.messages.count_tokens(
model=MODEL,
messages=messages,
)
print("estimated_input_tokens =", token_est.input_tokens)
try:
async with client.messages.stream(
model=MODEL,
max_tokens=4096,
system="你是一个严谨的软件架构评审助手,优先给出可执行建议。",
thinking={"type": "adaptive", "display": "summarized"},
output_config={"effort": "high"},
cache_control={"type": "ephemeral"}, # 自动缓存,适合多轮会话
messages=messages,
) as stream:
buf = []
async for text in stream.text_stream:
print(text, end="", flush=True)
buf.append(text)
final_msg = await stream.get_final_message()
return final_msg, "".join(buf)
except anthropic.RateLimitError:
# 真实生产环境里应该读取 retry-after 并指数退避
raise
except anthropic.APITimeoutError:
# 对长请求优先改为 stream,或增大 timeout
raise
async def main():
history = [
{"role": "user", "content": "我们准备把单体应用拆成 6 个服务。"},
{"role": "assistant", "content": "好的,请告诉我当前系统的模块边界和部署方式。"},
]
final_msg, text = await ask_claude(history, "请给我一个分阶段迁移计划。")
print("\nrequest_id =", final_msg._request_id)
asyncio.run(main())适用场景:后端服务、多轮助手、长文本输出、并发 API 网关。注意事项:Anthropic 官方 Python SDK 默认支持重试、超时、请求 ID 暴露;对高并发 async 场景,官方明确建议可切到 aiohttp backend;长请求尽量使用 streaming,且 Opus 4.8 应使用 adaptive thinking + effort,而不是采样参数。Messages API 本身是stateless,会话历史必须由你在应用层维护。
# 场景:长文档 / 长上下文分片 + 汇总
# 说明:Anthropic 没有规定固定 chunk 大小,下面是“先局部摘要、再全局综合”的工程模板
async def summarize_chunks(chunks):
requests = []
for i, chunk in enumerate(chunks):
requests.append({
"custom_id": f"chunk-{i}",
"params": {
"model": MODEL,
"max_tokens": 1200,
"messages": [{
"role": "user",
"content": f"<document index='{i}'>{chunk}</document>\n"
f"请先抽取关键事实,再给出 5 条摘要。"
}]
}
})
batch = await client.messages.batches.create(requests=requests)
print("batch_id =", batch.id)
# 生产环境中轮询 processing_status == 'ended' 后再取结果适用场景:大规模异步摘要、海量 chunk 并行处理、离线报告生成。注意事项:Batch API 官方定价是输入/输出各打五折,适合“对时延不敏感、对成本敏感”的工作负载;对于长文档问答,官方建议把长文档放在前面、问题放在最后、必要时让模型先抽取相关引用再回答,而不是把所有原文直接塞进单轮对话里硬问。
JavaScript
// 场景:Node.js 网关 / BFF / Edge 以外的服务端
// 覆盖:认证、流式输出、取消、重试、会话状态
import Anthropic from "@anthropic-ai/sdk";
const client = new Anthropic({
apiKey: process.env.ANTHROPIC_API_KEY,
maxRetries: 2,
timeout: 60_000,
});
const MODEL = "claude-opus-4-8";
async function runConversation(history, userInput) {
const stream = client.messages
.stream({
model: MODEL,
max_tokens: 4096,
system: "你是企业知识库问答助手;不知道就明确说不知道。",
thinking: { type: "adaptive", display: "summarized" },
output_config: { effort: "high" },
cache_control: { type: "ephemeral" },
messages: [
...history,
{ role: "user", content: userInput }
],
})
.on("text", (text) => process.stdout.write(text));
const full = await stream.finalMessage();
return full;
}
async function main() {
const history = [
{ role: "user", content: "这是第一轮背景信息:我们的系统基于事件总线。" },
{ role: "assistant", content: "收到,请继续。"}
];
const msg = await runConversation(history, "给我设计一个可审计的事件追踪方案。");
console.log("\nrequestId =", msg._request_id);
}
main().catch(console.error);适用场景:Node.js 服务端、SSE 转发、前后端分离架构中的后端代理层。注意事项:TypeScript/JavaScript SDK 默认也会对 连接错误、408、409、429、>=500 做指数退避重试;长请求官方建议使用 streaming。浏览器默认禁用该 SDK,只有显式 dangerouslyAllowBrowser: true 才能打开,因为会暴露密钥,不建议直接在前端持有 Anthropic API Key。
// 场景:并发请求
// 说明:对“互不依赖”的请求用 Promise.all;对超大规模离线任务优先 Batch API
async function fanOut(questions) {
return Promise.all(
questions.map((q) =>
client.messages.create(
{
model: MODEL,
max_tokens: 1200,
messages: [{ role: "user", content: q }],
},
{ maxRetries: 5 } // 单请求覆盖默认重试
)
)
);
}适用场景:多个独立查询、批量标签分类、分治式代理步骤。注意事项:Anthropic 官方对大规模批处理提供了单独的 Message Batches API,并且批任务有自己独立的限流模型;如果并发突然飙升,除了普通 429 外,还可能触发 acceleration limits,官方建议逐步升流而不是瞬时打满。
curl
# 场景:最小可复现调试 / CI / shell 脚本
# 注意:Opus 4.8 不要传非默认 temperature / top_p / top_k
curl https://sg.uiuiapi.com/v1/messages \
-H "content-type: application/json" \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-d '{
"model": "claude-opus-4-8",
"max_tokens": 2048,
"system": "你是一个中文技术文档助手,输出必须结构化。",
"thinking": {"type": "adaptive", "display": "summarized"},
"output_config": {"effort": "high"},
"messages": [
{"role": "user", "content": "请比较事件驱动与请求驱动架构的适用场景。"}
]
}'适用场景:故障排查、CI smoke test、平台无 SDK 环境。注意事项:认证核心是 API key;官方 SDK 默认会自动带上 anthropic-version: 2023-06-01,而你在 curl 中需要自己显式补齐。若你在 Opus 4.8 上继续传非默认采样参数,迁移指南明确说明会触发 400 错误。

开发实践与集成指南
Anthropic 官方对 prompt engineering 的建议非常明确:角色放 system,其余大部分业务内容尽量放到首个 user turn;使用 XML tags 分隔 instructions/context/examples/input;针对多文档和长上下文任务,把长文档放前面、查询放后面,并要求模型先引用再回答,通常更稳定。对于复杂任务,官方建议用 3–5 个 few-shot 示例,并用 <examples>/<example> 标签隔离,减少模型把示例误当成当前输入。
一个可落地的提示模板如下。这不是官方逐字模板,而是把 Anthropic 的建议收束成适合生产的通用写法:
<role>
你是企业级知识工作助手,优先保证可验证性、引用与边界说明。
</role>
<instructions>
1. 先判断问题是否需要引用上下文。
2. 若上下文不足,明确指出“不足以判断”。
3. 若上下文充分,先列出依据,再给结论。
4. 输出格式必须为:
- 结论
- 关键依据
- 风险与不确定性
</instructions>
<context>
{{retrieved_documents}}
</context>
<examples>
<example>
<input>……</input>
<output>……</output>
</example>
</examples>
<input>
{{user_query}}
</input>如果你需要中途改变策略,例如“从现在开始回答必须是 JSON”或“接下来的 3 轮只做文档抽取不做建议”,在 Opus 4.8 上优先用中途 system 消息,而不是重写整个历史;这样做最大的工程收益,是保住前缀缓存命中。

上图适用于典型企业集成:RAG 做证据召回,Prompt 组装器负责角色/约束/XML 结构,Claude 负责推理与工具规划,工具执行始终放在应用侧受控环境。Anthropic 官方文档把 Tools、Prompt Caching、Batch、Files、MCP 都放在这条链路的不同抽象层上;若是远程工具,TypeScript SDK 还可直接通过 MCP helpers 或 mcp_servers 接入。
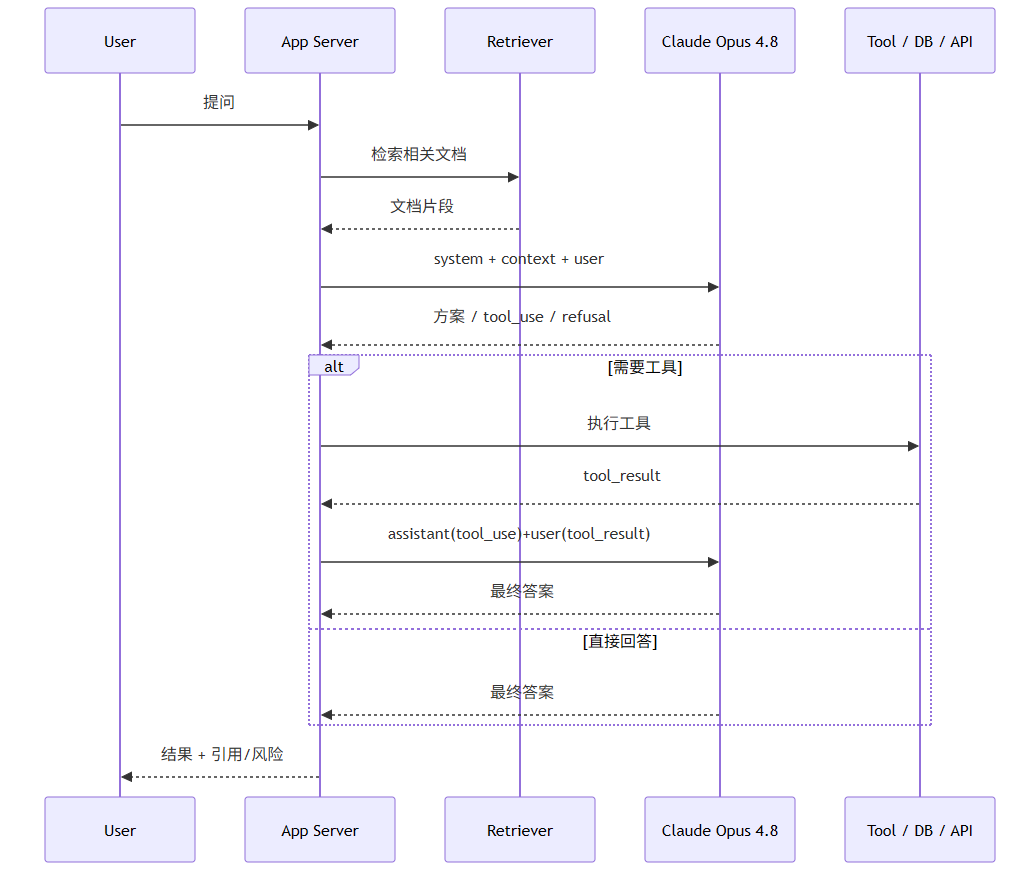
上下文保留策略。 Anthropic 官方推荐的主线是:短会话靠完整历史回传 + 自动 prompt caching,长会话靠server-side compaction,再辅以 token counting 预估;extended thinking 的历史思考块会被 Claude API 自动从未来上下文窗口计算中剥离,不需要你手工清理,但在tool use 循环未完成前,相关 thinking block 需要原样保留并回传。
RAG 实践。 Anthropic 文档把 RAG 定义为把外部知识库检索结果送入上下文,以提升事实性和可引用性;同时也提醒,RAG 的效果取决于检索质量,并在法律摘要等场景中建议采用summary-indexed documents / contextual retrieval 这类“先摘要、再排序、再精读”的高级变体。官方没有规定通用 chunk 大小,因此应把 chunking 视为工程参数而非模型参数:最稳妥的做法,是用 语义分段 + count_tokens 预估 + 引用优先回答。

性能 成本 与模型对比
官方定价。 Claude Opus 4.8 标准价为 输入 $5/MTok,输出 $25/MTok;5 分钟缓存写入为 $6.25/MTok,1 小时缓存写入为 $10/MTok,缓存命中/刷新读取为 $0.50/MTok。Fast mode 研究预览价为 $10/$50 per MTok,而 Batch API 价为 $2.50/$12.50 per MTok。Anthropic 还明确说明:1M 长上下文按标准单价计费,没有 long-context premium。
成本估算方法。 一个标准请求的最简公式是:
总成本 = 输入 tokens × 输入单价 + 输出 tokens × 输出单价 + 额外工具成本
若开启 prompt caching,则把输入部分拆成:cache_write + cache_read + uncached_input。Anthropic 官方明确指出:5 分钟缓存只要命中 1 次就回本,1 小时缓存命中 2 次回本;如果你能把长 system prompt、工具 schema、历史对话或大文档前缀缓存起来,成本和 ITPM 压力都能明显下降。
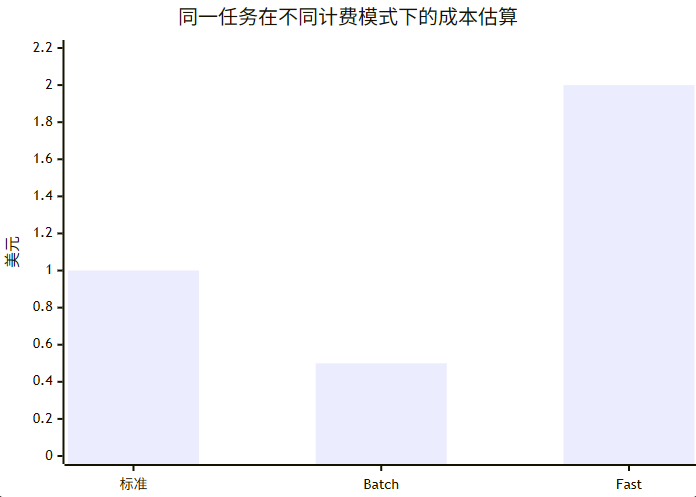
上图假设 100k input + 20k output。按 Opus 4.8 标准价:0.1×5 + 0.02×25 = $1.00;Batch 约为 $0.50;Fast mode 约为 $2.00。这只是单轮估算,未计入工具附加费、缓存读写或数据驻留加价。citeturn35view0turn34view1turn36view0
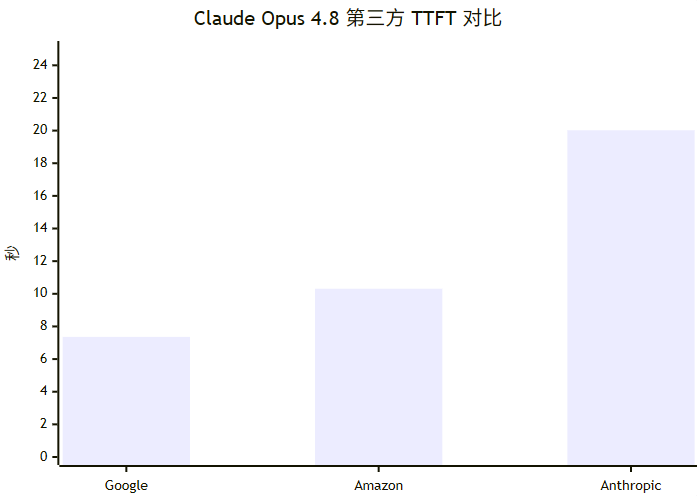
延迟与吞吐。 官方文档给了 streaming、timeout、keep-alive、fast mode 和 effort 等机制,但没有给出统一的端到端延迟/吞吐 SLA。官方能确认的是:长请求建议使用 streaming;Python/TypeScript SDK 默认超时约 10 分钟,并会在超时后自动重试两次;TypeScript SDK 还会根据大 max_tokens 动态拉长非流式请求的超时上限。第三方 Artificial Analysis 在 “Adaptive Reasoning, Max Effort” 设置下测得,Claude Opus 4.8 的首 token 延迟在不同提供商上约为 Google 7.36s、Amazon 10.31s、Anthropic 20.02s,输出速度约为 60.1–64.4 tokens/s;这些数字更适合作为选型参考,不应直接当成你的生产 SLO。
可得基准。 官方发布页强调 4.8 在编码、代理与知识工作中继续提升,并引用合作方测试数据,例如 Online-Mind2Web 84%、法律代理基准与 Super-Agent 成绩提升等。独立第三方方面,Artificial Analysis 的公开页面显示,Claude Opus 4.8(max)已位居其 Intelligence Index 前列;搜索捕获结果显示其 Intelligence Index 约为 61,并在当天的榜单中与顶级前沿模型并列第一梯队。由于该结果依赖其私有评测方法和具体 effort/provider 配置,建议把它视为横向信号,不要替代你自己的 task-specific eval。
对比表。
| 维度 | Claude Opus 4.8 | Claude Sonnet 4.6 | OpenAI GPT-4.1 |
|---|---|---|---|
| 官方定位 | Anthropic 最强、正式可用的通用模型 | Anthropic 当前最强 Sonnet 级模型之一,偏均衡生产负载 | OpenAI 高上下文通用模型;官方文档同时建议复杂任务优先从 GPT-5 起步 |
| 上下文窗口 | 1M;Foundry 启动时 200k | 1M | 1,047,576 tokens |
| 最大输出 | 128k | 64k | 32,768 |
| 标准价格 | $5 输入 / $25 输出 / MTok | $3 输入 / $15 输出 / MTok | $2 输入 / $8 输出 / MTok;缓存输入 $0.50 / MTok |
| Batch 价格 | $2.50 / $12.50 / MTok | $1.50 / $7.50 / MTok | 官方模型页给出 GPT-4.1 Batch 价格;与常规定价相比更低 |
| 采样参数 | 非默认 temperature/top_p/top_k 会 400;更推荐 adaptive thinking + effort |
官方未见与 Opus 4.8 相同级别限制说明;但 Claude 4.x 新模型总体转向 effort 控制 | 支持传统输出长度/上下文控制;本报告未展开其完整参数矩阵 |
| 延迟 | 官方未指定;第三方在 max effort 下测得 TTFT 约 7.36–20.02s,provider 依赖明显 | 官方未指定 | 官方未指定 |
| 适合场景 | 复杂编码代理、长程研究、多文档严谨分析 | 中高质量生产对话、RAG、客服、通用自动化 | 高上下文通用任务、跨平台 API 工作负载 |
开放问题与局限。 这份对比刻意优先采用官方资料,因此有三项内容需要明确标注“未指定”或“不可外推”:4.8 的底层架构细节、4.8 的单独知识截止日期、官方统一延迟/吞吐基线。另外,Anthropic 公告提到了 Claude Opus 4.8 System Card,但公开 system card 索引页截至本文撰写时尚未列出该条目,因此关于 4.8 的完整对齐/安全评估细节,当前公开可检索性仍不完整。
常见问题与故障排查
-
为什么会报 401 / AuthenticationError?
常见原因是ANTHROPIC_API_KEY未设置、密钥拼写错误,或你把前端浏览器直接暴露成了调用端。优先检查环境变量、服务端代理层,以及是否误把浏览器直连打开了。 -
为什么 Opus 4.8 一传
temperature=0.2就 400?
因为 Anthropic 官方迁移指南明确说明:Opus 4.8 上设置非默认temperature、top_p、top_k会返回 400。解决方式是删掉这些字段,改用thinking={"type":"adaptive"}与output_config.effort。 -
为什么以前的 prefill 技巧在 4.8 上失效?
因为官方说明 prefill 不支持 Opus 4.8。如果你以前靠预填助手回答来“卡格式”,应改用 structured outputs 或更强的系统/用户模板。 -
为什么长请求经常超时或挂住?
官方 SDK 已提示:长请求应优先改成 streaming;非流式、且max_tokens很大的请求,SDK 会认为它可能超过默认时限并报错或被中止重试。解决办法是:启用 streaming、增大 timeout、减少单轮输出长度。 -
为什么明明是多轮对话,模型却“失忆”了?
因为 Messages API 是 stateless。你必须把完整历史回传;历史里甚至可以包含 synthetic assistant messages。解决办法是自己维护messages历史,或结合 prompt caching/compaction 来做长会话管理。 -
为什么触发 429,即使平均流量不高?
官方文档说明除了普通 RPM/ITPM/OTPM 外,还可能触发 acceleration limits。如果你的组织突然陡增流量,也会被限。解决办法是遵从retry-after、做指数退避,并把放量改成渐进升流。 -
为什么缓存明明开了,成本和延迟却没降?
常见原因是你修改了缓存层级前面的内容,导致 cache invalidation;或者内容长度没达到模型的最小可缓存门槛。对 Opus 4.8,最小可缓存长度已降到 1,024 tokens,但改变tools → system → messages的前缀内容仍会使后续层级失效。 -
为什么 tool use 成本比预期高?
因为工具定义、tool_use、tool_result都会增加 token;服务端工具还可能有附加计费,例如 web search 为 $10 / 1,000 次搜索。解决办法是缩短 tool schema、限制max_uses、仅在确有必要时开放工具。 -
为什么会出现
model_context_window_exceeded?
Claude 4.5+ 在总输入加max_tokens超过窗口时,可能会先接受请求,随后在实际生成阶段以stop_reason: "model_context_window_exceeded"停止。解决办法是:请求前做 token counting,接近上限时启用 compaction、删旧 tool results、减少冗余历史。 -
为什么流式输出中断后不能像以前那样无缝恢复?
Anthropic 文档指出,对 Claude 4.6+ 的流恢复策略,应在新请求里加一个用户消息,提示“上一条响应被中断,请从这里继续”;不能再简单地把半截回答塞成新的 assistant 前缀。 -
为什么 Debug 日志里出现敏感内容?
TypeScript SDK 明确提醒:debug级别会记录 HTTP 请求和响应,请求/响应体中的敏感数据可能可见。解决办法是生产环境默认warn或error,并对日志系统做脱敏。 -
为什么 Files API 在某些平台不可用?
官方文档说明 Files API 可用于 Claude API、Claude Platform on AWS 和 Microsoft Foundry,但当前不支持 Amazon Bedrock 或 Vertex AI。若你是多云部署,要把上传与文件引用能力视为平台差异项。
安全 合规 与隐私
密钥与客户端边界。 最基本也最容易犯错的一条,是 Anthropic API Key 必须只存在于服务端。Python SDK 文档建议使用 .env / python-dotenv,TypeScript SDK 则默认禁用浏览器使用,并明确把开启浏览器支持命名成 dangerouslyAllowBrowser,就是在提醒你:API Key 暴露前端通常不是可接受的生产形态。
数据保留。 Anthropic 对 Claude API 提供 Zero Data Retention 选项:在 ZDR 安排下,客户数据在响应返回后不做静态存储,除非法规要求或为打击滥用所必需。官方同时强调:Messages API 与 Token Counting API 属于 ZDR 覆盖范围;但 Console/Workbench、Claude Managed Agents、消费者产品界面,以及第三方站点/第三方工具链,并不自动落入 ZDR 保护范围。更重要的是,即便是 ZDR/HIPAA 场景,若触发政策违规调查或法律要求,输入与输出仍可能被保留最长 2 年。
合规与 PHI。 对需要处理受保护健康信息的组织,Anthropic 提供 HIPAA-ready API access 与 BAA;但官方也划定了边界:HIPAA readiness 不覆盖 Claude consumer products、Console/Workbench、Bedrock、Vertex AI、Claude Platform on AWS、Microsoft Foundry、Claude Code,且很多 beta 特性默认不在 BAA 范围内。另一个容易忽略的约束是:如果你使用 structured outputs 或 strict: true 工具模式,JSON schema 会被单独编译和缓存;Anthropic 明确要求不要把 PHI 写进 schema 本身,PHI 只应出现在 message content 中。
输出审查建议。 Anthropic 的 guardrails 文档建议采用多层防御:用轻量模型做无害性预筛、对 jailbreak/prompt injection 做输入验证、在 system prompt 里强化伦理/法律边界、对滥用用户做节流或封禁,并持续监测模型输出以做迭代优化。对内容审核类业务,Anthropic 还专门给出了 moderation 指南,强调可以用 LLM 做多语言、可解释、可变更策略的审核,但也提醒:Claude 自身受 AUP 约束,某些高风险内容即便你提示“不要审核”,它也可能仍然拒绝或标记。
安全资质。 Anthropic Trust Center 的公开资源索引显示,官方提供 2025 Type 2 SOC 2 / CSA STAR L2 report、SOC 3 report、ISO 27001 certificate 等合规材料;如果你的采购、法务或安全团队需要证据链,这些材料应通过 Trust Center 或企业流程获取,而不是仅凭营销页说明。
示例工程与部署建议
下面给出一个小型、可生产化改造的示例工程。目标是:用 FastAPI + Anthropic Python SDK + 向量检索 + Prompt Caching + Streaming 做一个面向内部知识库的“严谨问答助手”。
claude-opus-48-rag-assistant/
├─ .env.example
├─ requirements.txt
├─ Dockerfile
├─ docker-compose.yml
├─ app/
│ ├─ main.py # FastAPI 入口
│ ├─ config.py # 模型、超时、重试、日志、限流配置
│ ├─ anthropic_client.py # SDK 封装、request_id、错误映射
│ ├─ prompts.py # system/user 模板与 XML tags
│ ├─ conversation.py # 会话历史持久化与中途 system 更新
│ ├─ rag.py # 检索、重排、引用拼接
│ ├─ caching.py # cache_control 与命中统计
│ ├─ observability.py # 指标、追踪、结构化日志
│ └─ schemas.py # Pydantic 输入输出模型
├─ tests/
│ ├─ test_prompts.py
│ ├─ test_rag.py
│ └─ test_api.py
└─ scripts/
└─ load_test.py # 并发压测与成本估算一个最小服务端入口可以写成下面这样:
# app/main.py
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from app.anthropic_client import ask_with_rag
app = FastAPI()
class ChatReq(BaseModel):
session_id: str
query: str
@app.post("/chat")
async def chat(req: ChatReq):
try:
return await ask_with_rag(req.session_id, req.query)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))对应的 Claude 封装层建议至少做五件事:记录 _request_id、读取 rate-limit headers、把 429/5xx/timeout 归一化、在长请求中强制 streaming、请求前调用 count_tokens 。这并不是“锦上添花”,而是 Anthropic 官方文档已经明确暴露出来的生产抓手:请求 ID 用于排障,rate-limit headers 用于回退窗口控制,token counting 用于避免窗口溢出。
部署建议。
本地开发阶段建议直接用 docker compose 起一个最小栈,方便做 .env、向量库、日志代理和 API 服务的一致化。云上部署时,如果你的需求是最低接入摩擦与 Anthropic 特性完整性,优先用 Anthropic Claude API;如果你的组织强依赖特定云账号治理,再考虑 Bedrock/Vertex/Foundry,但要把 1M context、Files API、自动缓存、Fast mode、数据驻留与计费差异作为平台选择矩阵中的显式项。
性能测试与监控指标。
建议把以下指标做成默认面板:p50/p95/p99 TTFT、end-to-end latency、output tokens/s、input/output/cache read/cache write tokens、429/5xx/timeout rate、tool call success rate、refusal rate、model_context_window_exceeded rate、cache hit ratio、cost per request、cost per successful task。其中最关键的三项,是请求级 _request_id、rate-limit 头和cache 命中率:前者用于追支持工单,后两者决定你是否能把 Opus 4.8 跑进“可控成本、可控延迟”的生产区间。
最终建议。
如果你要今天就落地,我建议采用下面的默认策略:
模型 用 claude-opus-4-8;推理 用 thinking: adaptive + effort: high;长响应 一律 streaming;多轮会话 开 cache_control: {"type":"ephemeral"};大批量离线任务 走 Batch API;动态规则调整 用中途 system 消息;RAG 采用“检索片段 + 先引用后回答”;高风险输出 前后各加一层 guardrail;所有请求 记录 request_id、token、cost 和 retry-after。这样做最符合 Anthropic 官方文档当前暴露出的能力边界,也最符合 Opus 4.8 的工程设计哲学。
版权信息: 本文由界智通(jieagi)团队编写,图片、文本保留所有权利。未经授权,不得转载或用于商业用途。
本文发布于2026年05月30日11:54,已经过了45天,若内容或图片失效,请留言反馈 转载请注明出处: 界智通
本文的链接地址: https://www.jieagi.com/aizixun/121.html
-

GPT-5-Codex保姆级教程:获取OpenAI APIKey与安装 Codex CLI使用教程全面指南
2025/09/17
-
2025最新:Claude Pro 与 Max 区别详解与订阅指南
2025/08/26
-
Gemini 报错 "Something went wrong" 终极解决指南
2025/11/27
-
Cursor权威指南:从注册入门到精通AI驱动编程工作流(含国内注册与验证说明)
2025/08/27
-
2025最新保姆级教程:如何获取Claude API Key?从注册到Python调用,一篇搞定!
还在为如何申请 Claude API Key 而头秃吗?随着 Claude 4.5 Sonnet 在编程能力上的强势崛起,越来越多的开发者开始转向 Anthropic 的阵营。本文将通过“保姆级”的图文实操,带你一步步解决账号注册、手机号验证、API Key 获取及额度充值等难题,并附带 Python 极简调用示例。无论你是想接入 LangChain 还是自己在这个强大的模型上跑 Demo,这篇文章都能帮你避开 99% 的坑!
2025/11/15
-
【实测有效】Gemini 3 / Google Antigravity 授权登录无反应、无权限?全平台解决办法汇总指南
2025/11/22
-
[2025最新] ChatGPT Plus 订阅终极指南:四种充值方案与深度解析:为什么它值$20?
2025/11/13
-
Grok-4.1 深度拆解:马斯克的“叛逆”AI怎么接入?xAI Grok API Key 获取及开发攻略
想要体验马斯克旗下xAI的Grok大模型?本文详细拆解 Grok API Key 获取的全流程,从账号登录、控制台设置到API Key生成,并附带完整的Python调用代码示例。解决开发者在申请过程中遇到的支付、权限等常见问题,助你快速将“叛逆”的Grok集成到自己的应用中。
2025/11/18
-
Google AI Pro 有什么功能?Google AI Pro 生态系统深度报告以及订阅会员权益功能全面分析
2025/11/29
-
国内开发者玩转Claude:最新Claude 4模型解析与API Key获取攻略
Claude 4核弹来袭:国内开发者别再错过这把金钥匙! 你还在用老掉牙的AI模型苦苦挣扎,项目卡在瓶颈?醒醒!Anthropic的Claude 4系列横空出世,像一枚AI核弹,炸翻了整个行业天花板。国内开发者别愁,支付墙、网络坑,我来戳破这些烂事儿。跟着我这个行业老鸟,一步步上手Claude 4,让你的代码飞起,项目变身AI怪兽。准备好了吗?咱们直奔干货!...
2025/07/20





![[2025最新] ChatGPT Plus 订阅终极指南:四种充值方案与深度解析:为什么它值$20?](https://www.jieagi.com/content/uploadfile/202511/249b1763003156.png)




暂无评论





太好看了,快点更新!
国内开发者玩转Claude:最新Claude 4模型解析与API Key获取攻略
这是系统生成的演示评论
国内开发者玩转Claude:最新Claude 4模型解析与API Key获取攻略