
 界智通
界智通 Claude Fable 5 全面解析:模型下架风波后,开发者该怎么获取APIKey调用?
 jieagi_Pan
jieagi_Pan 一、为什么 Claude Fable 5 值得开发者关注?
过去一年,大模型之间的竞争已经不只是"谁回答得更聪明",而是逐渐转向一个更实际的问题:模型能不能长时间稳定地完成复杂任务?
这个变化对开发者来说感受尤其明显。以前我们更多关心模型能不能写一段代码、改一个函数、总结一篇文章;现在,越来越多团队开始把模型放进真实业务流里——让它读完整个代码仓库、交叉分析多份文档、连续调用外部工具、维持多轮上下文,甚至承担起接近"半自动项目助理"的角色。Claude Fable 5 的出现,正是瞄准了这类场景。
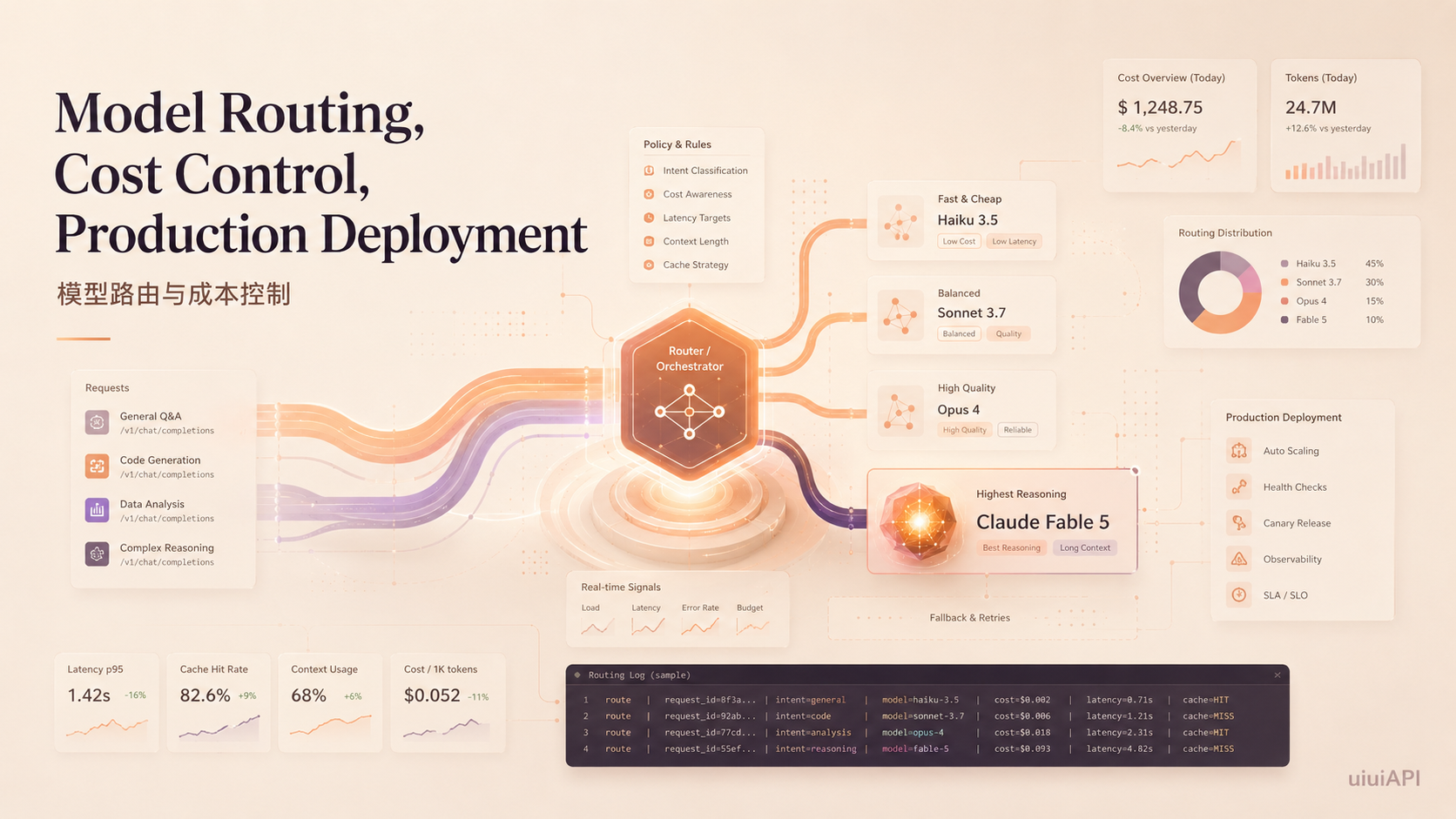
根据 Anthropic 官方文档,Claude Fable 5 的 API ID 为 claude-fable-5,被定位为 Anthropic 目前最强的广泛发布模型,面向需要最高能力上限的工作负载。它支持文本和图像输入、文本输出,具备多语言能力和视觉理解,可通过 Claude API、Claude Platform on AWS、Amazon Bedrock、Google Cloud 和 Microsoft Foundry 等渠道调用。
更关键的是,它的规格设计明显偏向"重任务":1M tokens 上下文窗口、最高 128k tokens 输出,并且始终开启 adaptive thinking(自适应思考)机制。相比常规聊天模型,它更像是为长链路推理、复杂代码工程和多工具编排量身打造的高端选项。
也正因如此,Claude Fable 5 并不适合拿来做低成本闲聊或简单分类,它真正的价值在于:处理那些便宜模型容易断线、忘上下文、工具调用混乱、跨文件一致性差的复杂任务。

一次不大不小的插曲:发布、下架,再到恢复
Claude Fable 5 的上线过程并不平静,这段经历本身也值得开发者了解——它直接关系到接入的稳定性预期。
- 6 月 9 日发布:Anthropic 同时推出 Claude Fable 5(面向公众,带安全分类器)和能力对等的 Claude Mythos 5(仅限 Project Glasswing 可信合作伙伴使用,不带分类器)。Fable 5 在软件工程、长时程代理任务、知识工作和视觉理解上表现突出。
- 6 月 12 日全球下架:美国政府以国家安全为由发出出口管制指令,Anthropic 在无法逐一核验用户资质的情况下,选择全球暂停访问以规避合规风险。
- 6 月 30 日管制解除,7 月 1 日恢复访问:经过协商与安全分类器升级,商务部撤销限制,Fable 5 于 7 月 1 日起重新全球可用;Mythos 5 仍维持有限访问。
恢复后,Fable 5 已在 Claude.ai、Claude Platform、Claude Code、Claude Cowork 等平台上线,并陆续覆盖 AWS、Google Cloud、Microsoft Foundry。付费计划方面,Pro、Max、Team 及部分 Enterprise 用户在 7 月 7 日前可使用 Fable 5 抵扣至多 50% 的周使用额度,此后转为按使用积分(usage credits)计费。API 调用则从一开始就按标准 token 单价计费,不受这一窗口期影响。
这段插曲对开发者的实际启示是:接入任何前沿模型时,都应该提前设计 fallback 策略——不只是应对模型报错,也要应对政策性、地缘性的临时不可用。
二、模型定位:不是"更贵的聊天模型",而是高端任务层
如果只看名字,很多人会把 Claude Fable 5 理解成 Claude 系列的一次常规升级。但从官方定位和规格来看,它更像是 Anthropic 单独为高端任务拉出来的一层能力模型。
在 Anthropic 的模型选择建议中,如果开发者不确定该用哪个模型,官方建议先从 Claude Opus 4.8 开始;只有当工作负载明确需要"最高可用能力"时,才升级到 Claude Fable 5。这个细节其实很关键:它暗示 Fable 5 并不是默认最划算的选项,而是为高难度任务准备的"能力上限优先"模型。
适合 Fable 5 的典型任务大致可以归为四类:
第一类,复杂代码工程。 比如大型代码库重构、跨模块 bug 定位、复杂迁移方案设计、长时间运行的 coding agent 任务。这类场景不是简单生成代码,而是要求模型长期保持上下文、理解模块间依赖、反复自我验证。
第二类,超长文档分析。 比如企业制度、合同、技术规范、产品需求文档、研发资料库等。1M tokens 上下文的价值,在这类场景里会体现得非常直接。
第三类,多工具 Agent。 当模型需要连续调用搜索、数据库、代码执行、文件读取、API 查询等工具时,它的状态管理能力和错误恢复能力会直接决定最终结果的可靠性。
第四类,高价值知识工作。 比如技术调研、竞品分析、架构评审、投研报告、复杂方案设计。这类任务单次调用成本偏高,但如果能显著节省人工时间,仍然可能是划算的。
所以对开发者来说,Fable 5 更合理的用法不是"全站默认替换",而是作为模型路由体系里的高端层:简单任务交给低成本模型,中等复杂度任务交给 Opus、Sonnet 等通用模型,真正复杂、长上下文、多工具的任务再路由到 Fable 5。

三、核心能力:长上下文、长输出与复杂任务的稳定性
Claude Fable 5 最值得关注的三项能力,是 1M 上下文、128k 输出、adaptive thinking。
1. 1M tokens 上下文
1M tokens 上下文意味着模型可以一次性接收非常大的资料量。对开发者而言,这不只是"能塞更多文字",而是会改变应用的设计方式。
以前做长文档问答,通常需要切片、召回、重排、再拼接,这个流程容易丢信息,也容易让模型只看到局部内容。Fable 5 的长上下文让很多场景可以更直接地处理完整资料,尤其适合:
- 大型代码仓库分析
- 多份合同或制度的交叉比对
- 长篇技术文档审查
- 产品需求与实现方案的一致性检查
- 多轮 Agent 的状态保留
不过长上下文并非没有代价。上下文越长,成本和延迟越容易上升。生产环境中仍然建议配合 RAG、缓存、摘要和分层路由,而不是每次都把全部资料一股脑塞进去。
2. 最高 128k tokens 输出
128k 输出对代码生成、长报告生成、迁移方案、批量结构化文档的价值很直接。比如让模型输出完整接口文档、长篇技术方案、多文件重构建议时,不容易因为输出长度不够而被截断。
这也要求开发者重新设置 max_tokens:由于 Fable 5 默认带思考机制,max_tokens 不只是控制可见回答的长度,也会占用模型完成复杂任务所需的推理空间。如果沿用旧模型偏小的输出上限,很可能出现内容还没讲完就被截断的情况。
3. Adaptive thinking(自适应思考)
Claude Fable 5 使用自适应思考机制,模型会根据任务难度自行决定投入多少推理过程。根据 Anthropic 的迁移文档,Fable 5 不支持关闭 thinking,开发者应该通过 effort、max_tokens、提示词结构和任务边界来控制效果,而不是试图关掉它。
这也意味着调参的重点需要转移:不再是传统的 temperature、top_p,而是更工程化的控制方式:
- 明确任务目标
- 明确输出格式
- 明确验收标准
- 控制 effort 档位
- 配合工具调用和缓存
- 持续监控成本与延迟

四、API 调用方式:Messages API 仍是核心入口
如果你不想单独申请 Anthropic 官方 API Key,也可以通过 uiuiAPI 获取APIKey,开发者能快速调用 Claude Fable 5。uiuiAPI 支持 OpenAI 兼容格式,一个 API Key 即可接入 Claude、GPT、Gemini、Grok、DeepSeek 等多类模型。只需将接口地址改为 https://uiuiapi地址/v1,模型名填写 claude-fable-5,即可在常见客户端或项目中快速测试使用,更适合多模型接入、项目开发和商业化运营场景。
从开发体验来看,Claude Fable 5 的接入方式并不复杂,仍然使用 Anthropic 的 Messages API,模型 ID 为:
claude-fable-5Fable 5 可在 Claude API、Claude Platform on AWS、Amazon Bedrock、Google Cloud 和 Microsoft Foundry 上使用。
Python 调用示例
import os
from anthropic import Anthropic
client = Anthropic(
api_key=os.environ["ANTHROPIC_API_KEY"]
)
response = client.messages.create(
model="claude-fable-5",
max_tokens=4096,
output_config={
"effort": "high"
},
system=(
"你是一名资深 AI 平台架构师。"
"请用清晰、可执行、面向开发者的方式回答。"
"如遇到不确定信息,请明确标注'需验证'。"
),
messages=[
{
"role": "user",
"content": "请帮我设计一个支持多模型路由、限流和成本统计的大模型 API 聚合平台架构。"
}
]
)
print(response.content[0].text)curl 调用示例
curl https://uiuiapi.com/v1/messages \
-H "Content-Type: application/json" \
-H "X-API-Key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-d '{
"model": "claude-fable-5",
"max_tokens": 4096,
"output_config": {
"effort": "high"
},
"system": "你是一名资深 AI 平台架构师,请用工程化、可落地的方式回答。",
"messages": [
{
"role": "user",
"content": "请分析 Claude Fable 5 在企业 Agent 系统中的适用场景。"
}
]
}'需要提醒一点:Fable 5 内置了安全分类器,遇到高风险提示时可能直接以 stop_reason: "refusal" 返回(HTTP 200,而非报错),所以调用侧的错误处理逻辑需要单独覆盖这种情况,不能只按普通异常来处理。
流式响应建议
对于 Fable 5 这类可能输出较长内容的模型,建议默认开启流式响应,这样可以减少用户等待感,也能降低长响应超时的概率。
前端或服务端代理大致可以按这个思路处理:
- 用户请求进入 API 网关;
- 网关记录 trace_id、用户 ID、模型 ID;
- 后端请求 Claude Messages API,并开启 stream;
- 边接收边转发给前端;
- 最终落库 token 用量、耗时、stop_reason、成本估算和错误信息。
这类模型更适合"边生成边展示",尤其是技术报告、代码审查、长文档总结、Agent 执行过程说明等场景。
五、参数配置:重点不在 temperature,而在 effort 与任务结构
很多开发者接入新模型时,第一反应是问:temperature 设多少?top_p 设多少?
但在 Claude Fable 5 上,真正重要的不是这些传统采样参数,而是:
output_config.effort
max_tokens
system prompt
messages 上下文结构
tools 工具定义
stream 是否开启
fallback 策略Anthropic 的迁移说明提到,Fable 5 使用 adaptive thinking,建议从较高的 effort 档位开始评估;同时,assistant prefill 这类旧式用法也不适合直接照搬迁移。
effort 怎么选?
可以按任务价值分层来考虑:
| 场景 | 建议 effort | 说明 |
|---|---|---|
| 简单问答、短摘要 | 不建议使用 Fable 5 | 换低成本模型更划算 |
| 技术方案分析 | high | 兼顾质量与可控成本 |
| 复杂代码重构 | high / xhigh | 需要更强推理和上下文保持 |
| 长时程 Agent | high 起步 | 重点观察成功率、成本和工具轮数 |
| 高风险决策 | xhigh + 人工复核 | 不建议完全自动化 |
比较稳妥的做法是先用 high 做基线评估,再挑少量最复杂的任务测试 xhigh。不建议一上来就全部拉满档位,否则成本很容易失控。
六、成本与价格:能力很强,但价格也不便宜
Claude Fable 5 的定位很明确:高端能力,高端价格。
根据 Anthropic 官方定价,Claude Fable 5 的费用为:
- 输入:$10 / MTok
- 输出:$50 / MTok
- 5 分钟缓存写入:$12.50 / MTok
- 1 小时缓存写入:$20 / MTok
- 缓存命中与刷新:$1 / MTok
这个价格是 Claude Opus 4.8 的两倍。举个例子,如果一个请求输入 120k tokens、输出 8k tokens,不考虑缓存,大致成本是:
输入成本:0.12 × 10 = $1.20
输出成本:0.008 × 50 = $0.40
单次合计:约 $1.60对普通聊天场景来说,这个价格显然偏高;但如果它替代的是工程师几个小时的复杂分析,或者帮助企业完成一次代码迁移评估,这笔成本反而可能相当合理——尤其是配合 Prompt Caching 之后,重复上下文的命中价格能降到标准输入价的十分之一,长期跑 Agent 任务时能省下不少钱。
所以,Fable 5 的成本优化重点不是"压低单价",而是做好模型路由:
简单任务:低成本模型
中等任务:通用强模型
复杂任务:Claude Fable 5
离线批处理:Batch API(输入输出各半价)
重复上下文:Prompt Caching在 API 聚合平台或企业内部模型网关中,建议单独给 Fable 5 设置预算、限流、并发和调用白名单,避免被当成普通聊天模型随意消耗。
七、数据保留与合规:上线前必须重点确认
Claude Fable 5 还有一个容易被忽略、但非常重要的限制:数据保留策略。
根据 Anthropic 官方文档,Claude Fable 5 和 Claude Mythos 5 属于 "Covered Models",需要 30 天数据保留,且不支持 Zero Data Retention(零数据保留)——这一点即便是原本已经签了零保留协议的企业客户,也无法豁免。
这对企业客户、API 平台、金融、医疗、政企项目尤其重要。如果你的业务要求:
- 零数据保留;
- 严格本地化;
- 敏感数据不可离开指定区域;
- 对供应商数据处理有严格审计要求;
那么在接入 Fable 5 之前,务必先做一轮合规评估——不能只看模型能力强不强,还要看数据保留、日志、隐私协议、客户授权和业务边界是否匹配。
实际落地时,建议至少做三件事:
- 在产品说明中明确模型供应商和数据处理边界;
- 对敏感业务默认不走 Fable 5,除非用户明确授权;
- 后台保留模型调用日志,但不要保存不必要的原始敏感内容。
对于 API 聚合平台来说,还可以在模型说明里加一句提示:该模型适合复杂任务,不建议输入高度敏感信息;企业客户如有严格的数据保留要求,应先确认合规策略再接入。

八、适用场景:哪些任务真正适合 Claude Fable 5?
复杂代码项目分析。 让模型阅读多个文件,判断某个功能为什么异常,给出重构建议,并生成可执行的修改步骤。Fable 5 的长上下文和复杂推理能力在这里更容易体现价值。
企业知识库深度问答。 当用户的问题不是简单检索,而是需要跨多个文档综合判断时,Fable 5 比普通模型更适合承担"分析层"的角色。
长时程 Agent 工作流。 比如自动调研、自动写报告、自动生成方案、自动拆解任务、连续调用工具并回写结果。Fable 5 的优势在于更容易保持任务目标,不容易在长链路中"跑偏"。
架构设计与技术决策。 比如模型路由系统设计、API 网关方案、成本核算、故障回退策略、安全合规设计等。这类问题往往没有单一标准答案,需要综合判断。
高质量内容生产。 用于生成深度技术文章、行业研究报告、产品白皮书、开发者文档时,Fable 5 的长输出和复杂结构控制能力比较有用。
九、不适合的场景:不要什么都上 Fable 5
再强的模型,也不应该被滥用。以下场景不建议优先使用 Claude Fable 5:
- 简单客服问答
- 短文本改写
- 普通翻译
- 简单分类
- 轻量摘要
- 高频低价值请求
- 对数据保留极其敏感的场景
- 对延迟要求极低的实时交互
这些任务用更便宜、更快的模型通常就够了。Fable 5 应该被放在"高价值、低频、复杂"的任务层,而不是成为默认模型。
十、提示词建议:让 Fable 5 更像工程助手,而不是聊天机器人
Fable 5 的提示词最好写得更像一份工程任务书,而不是随口一问。推荐的结构是:
你是……
你的目标是……
你需要参考……
输出必须包含……
如果遇到不确定信息,请标注。
如果存在风险,请单独输出。举个例子:
你是一名资深 AI 平台架构师。
请基于以下需求,设计一个支持多模型路由的大模型 API 网关方案。
要求:
1. 先给结论;
2. 再给系统架构;
3. 说明模型路由策略;
4. 说明限流、计费、日志和错误回退;
5. 给出最小可落地版本;
6. 不确定的信息请标注"需验证"。
输出格式:
- 总体结论
- 架构设计
- 路由策略
- 成本控制
- 风险点
- 落地步骤这种写法比"帮我分析一下"稳定得多,也更适合接入生产系统。
十一、生产部署建议:模型网关比单点调用更重要
如果只是个人测试,直接调用 Claude API 就够了。但如果要上线到真实业务,建议通过模型网关统一管理。一个比较稳妥的生产架构大致是这样:
用户请求
↓
API 网关 / 鉴权
↓
任务分类器
↓
模型路由
├─ 简单任务:低成本模型
├─ 中等任务:通用强模型
└─ 高复杂任务:Claude Fable 5
↓
Prompt 模板层
↓
工具调用 / RAG / 文件解析
↓
流式响应
↓
日志、计费、限流、监控上线前建议重点监控这些指标:
- 单次请求 token 成本
- 平均响应时间
- 流式首 token 时间
- refusal rate(拒答率)
- fallback 成功率
- 工具调用轮数
- 用户任务完成率
- 缓存命中率
- 不同模型的性价比对比
尤其是 API 聚合平台,不建议只做"模型转发"。真正专业的平台应该能做模型分层、成本提醒、错误回退、并发控制和日志脱敏,这样用户体验会明显更稳定。
十二、总结:把 Claude Fable 5 当作"高端任务加速器"来用
Claude Fable 5 最大的价值,不是便宜,也不是响应最快,而是它为复杂任务提供了更高的能力上限。它适合:
- 长上下文场景
- 复杂代码工程
- 多工具 Agent
- 深度研究
- 企业知识分析
- 高质量技术内容生成
- 高价值任务自动化
但它也有明显门槛:
- 成本较高
- 延迟可能更高
- 需要合理设置 effort
- 需要做好数据保留评估
- 需要模型路由和 fallback 机制
- 不适合所有请求默认使用
对开发者和平台方来说,最合理的策略是:不要把 Claude Fable 5 当成普通聊天模型,而要把它作为高端任务层,纳入完整的模型路由、成本控制和生产监控体系里。
如果你的业务正在做 AI Agent、代码助手、企业知识库、开发者工具或大模型 API 聚合平台,Claude Fable 5 值得认真评估——但真正上线时,建议先从少量高价值场景灰度验证,而不是全量替换现有模型。
参考资料
- Anthropic Claude Models Overview:Claude Fable 5 的模型定位、上下文、输出长度与可用平台
- Anthropic Pricing:Claude Fable 5 的输入、输出、缓存价格
- Anthropic Migration Guide:Fable 5 的迁移、effort 与 adaptive thinking 相关说明
- Anthropic API and Data Retention:Fable 5 的 30 天数据保留要求
- Anthropic 官方发布说明:Claude Fable 5 与 Claude Mythos 5 的发布背景
https://www.anthropic.com/news/fable-mythos-access
版权信息: 本文由界智通(jieagi)团队编写,图片、文本保留所有权利。未经授权,不得转载或用于商业用途。
转载请注明出处: 界智通
本文的链接地址: https://www.jieagi.com/aizixun/123.html
-

GPT-5-Codex保姆级教程:获取OpenAI APIKey与安装 Codex CLI使用教程全面指南
2025/09/17
-
2025最新:Claude Pro 与 Max 区别详解与订阅指南
2025/08/26
-
Gemini 报错 "Something went wrong" 终极解决指南
2025/11/27
-
Cursor权威指南:从注册入门到精通AI驱动编程工作流(含国内注册与验证说明)
2025/08/27
-
2025最新保姆级教程:如何获取Claude API Key?从注册到Python调用,一篇搞定!
还在为如何申请 Claude API Key 而头秃吗?随着 Claude 4.5 Sonnet 在编程能力上的强势崛起,越来越多的开发者开始转向 Anthropic 的阵营。本文将通过“保姆级”的图文实操,带你一步步解决账号注册、手机号验证、API Key 获取及额度充值等难题,并附带 Python 极简调用示例。无论你是想接入 LangChain 还是自己在这个强大的模型上跑 Demo,这篇文章都能帮你避开 99% 的坑!
2025/11/15
-
【实测有效】Gemini 3 / Google Antigravity 授权登录无反应、无权限?全平台解决办法汇总指南
2025/11/22
-
[2025最新] ChatGPT Plus 订阅终极指南:四种充值方案与深度解析:为什么它值$20?
2025/11/13
-
Grok-4.1 深度拆解:马斯克的“叛逆”AI怎么接入?xAI Grok API Key 获取及开发攻略
想要体验马斯克旗下xAI的Grok大模型?本文详细拆解 Grok API Key 获取的全流程,从账号登录、控制台设置到API Key生成,并附带完整的Python调用代码示例。解决开发者在申请过程中遇到的支付、权限等常见问题,助你快速将“叛逆”的Grok集成到自己的应用中。
2025/11/18
-
Google AI Pro 有什么功能?Google AI Pro 生态系统深度报告以及订阅会员权益功能全面分析
2025/11/29
-
OpenAI GPT-5 深度解析:API Key定价与ChatGPT(Free, Plus, Pro)用户的区别
2025/08/08





![[2025最新] ChatGPT Plus 订阅终极指南:四种充值方案与深度解析:为什么它值$20?](https://www.jieagi.com/content/uploadfile/202511/249b1763003156.png)




暂无评论





太好看了,快点更新!
国内开发者玩转Claude:最新Claude 4模型解析与API Key获取攻略
这是系统生成的演示评论
国内开发者玩转Claude:最新Claude 4模型解析与API Key获取攻略