
 界智通
界智通 深度解析 🍌 Nano Banana Pro (Gemini 3 Pro Image):从入门到精通的全场景实战指南
 jieagi_Pan
jieagi_Pan 文章摘要:
在 2025 年的 AI 生成图像领域,"🍌 Nano Banana Pro" 以一种极具戏剧性的方式横空出世。这个听起来略带戏谑的名字背后,实则是 Google DeepMind 最新的旗舰级图像生成模型——Gemini 3 Pro Image。本文将作为一篇超万字的深度技术白皮书,详尽解答开发者与创作者最关心的两个核心问题:“🍌 Nano Banana Pro 怎么用”以及“🍌 Nano Banana Pro 在哪里用”。我们将深入剖析其基于推理引擎的底层架构,对比 Midjourney V6 与 Flux.2 的优劣,并提供从 Adobe Firefly 图形界面操作到 Google Vertex AI Python SDK 开发的全链路教程。无论你是追求极致画质的设计师,还是寻求自动化集成的全栈工程师,这份报告都将为你提供详实的操作手册与行业洞察。

第一章:现象级爆红背后的技术变革 —— 什么是 Nano Banana Pro?
1.1 从 "Nano Banana" 到 Gemini 3 Pro Image 的演进史
在人工智能的发展史上,很少有一个模型的代号能像 "Nano Banana" 这样深入人心。2025 年下半年,在大模型竞技场(LMSYS Chatbot Arena)的盲测排行榜上,一个匿名模型以惊人的胜率击败了当时的市场霸主 Midjourney V6 和 DALL-E 3。社区挖掘其代号为 "Nano Banana"(纳米香蕉),这迅速成为了技术圈的一个热梗。
这个代号并非随意的恶作剧,而是 Google 内部对于 Gemini 3 Pro Image 模型的早期测试命名。它的出现标志着图像生成技术发生了一次根本性的范式转移:从单纯的“像素扩散概率模型”转向了“语义推理与生成模型”。与其前代 Gemini 2.5 Flash Image(代号 Nano Banana)相比,Pro 版本(Gemini 3 架构)引入了更强大的逻辑推理核心。
在传统的扩散模型(Diffusion Model)中,AI 往往像是一个只懂关键词拼接的画师,它并不真正理解“三个人排队,中间的人拿着红伞”这种复杂的逻辑关系。而 Nano Banana Pro 利用 Gemini 3 的大型语言模型(LLM)能力,在生成像素之前,会先进行“思考”。它会通过内置的推理引擎(Reasoning Engine)解析 Prompt 中的空间关系、数量逻辑和物理常识,然后再指导图像生成。这种“先思考,后绘画”的机制,使其在处理复杂构图、精准文本渲染以及多步指令遵循上,展现出了前所未有的能力。
尽管 Google 最终将其正式命名为 Gemini 3 Pro Image,但 "Nano Banana Pro" 这一名称因其亲民性和早期的病毒式传播,已被社区广泛接纳,甚至 Google 官方在部分宣传中也保留了香蕉的 Emoji,体现了一种技术巨头的幽默感。
1.2 核心技术护城河:为什么它比 Midjourney 更“聪明”?
Nano Banana Pro 的核心优势不在于画面的“艺术滤镜”有多重,而在于其“工程化”的精确性。这主要得益于以下几个架构创新:
- 逻辑门控机制 (Logic Gate) :这是 Nano Banana Pro 与传统模型最大的区别。当用户输入“生成 20 个苹果”时,传统模型可能会生成一堆红色的圆球,数量随机。而 Nano Banana Pro 会启动枚举逻辑(Enumeration Logic),严格尝试遵循数量约束;当用户要求“左边是猫,右边是狗”时,它会启动空间逻辑(Spatial Logic),确保对象不会融合或位置错乱。
- 独立的符号推理引擎 (Symbolic Reasoning Engine) :为了解决 AI 画图“不识字”的顽疾,Google 将OCR(光学字符识别)技术的逆过程融入了生成端。模型在内部计算字符的笔画结构、字间距(Kerning)和排版布局,从而能生成 100% 拼写正确且符合设计美学的文字海报。这使得它在电商海报、Logo 设计等商业场景中具有不可替代的价值。
- 多模态上下文窗口 (Multimodal Context Window) :Nano Banana Pro 支持多达 14 张参考图像的输入。这意味着用户不再需要复杂的 LoRA 训练,仅通过上传参考图(如产品图、角色三视图),就能在保持特征一致性的前提下生成新场景。这种“上下文学习”(In-Context Learning)能力,直接打通了从素材库到最终成品的自动化链路。
第二章:🍌 Nano Banana Pro 在哪里用?—— 全平台接入生态详解
对于想要立即上手体验的用户来说,最大的困惑往往在于“入口太多,不知如何选择”。Nano Banana Pro 的服务生态可以分为三个层级:Google 原生生态(适合极客与企业)、创意软件集成(适合设计师)以及第三方聚合平台(适合尝鲜用户)。
2.1 Google 原生生态体系:最纯粹的体验
2.1.1 Gemini Advanced (Web & App)
这是普通消费者接触 Nano Banana Pro 最直接的途径。包含在会员权益中。
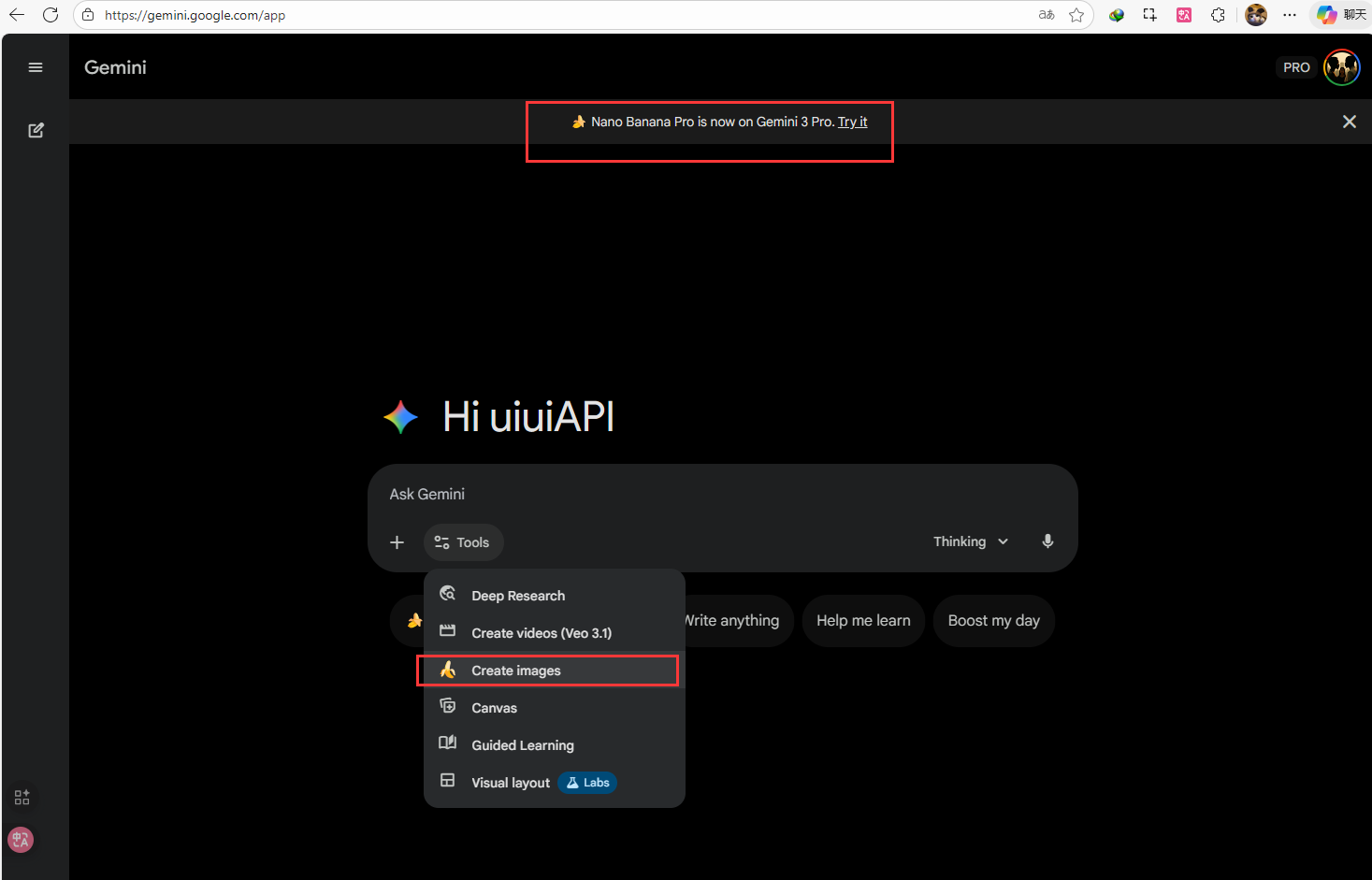
- 入口:Google Gemini 官网或移动端 App。
- 门槛:通常需要订阅 Google One AI Premium 计划(Gemini Advanced)。
- 体验:通过自然语言对话进行交互。用户可以直接输入“生成一张带有‘SALE’字样的霓虹灯海报”,模型会即时反馈。
- 优势:支持多轮对话修改(Multi-turn editing)。例如,生成图片后,你可以继续说“把背景换成蓝色”、“让文字更亮一点”,AI 会在保持原图主体不变的情况下进行局部重绘 12。
- 局限:免费版或基础版往往有严格的每日配额(如每日 2-3 张 Pro 级图片),且在高负载时可能会降级为 Flash 模型,建议升级Pro或其他等级的会员。
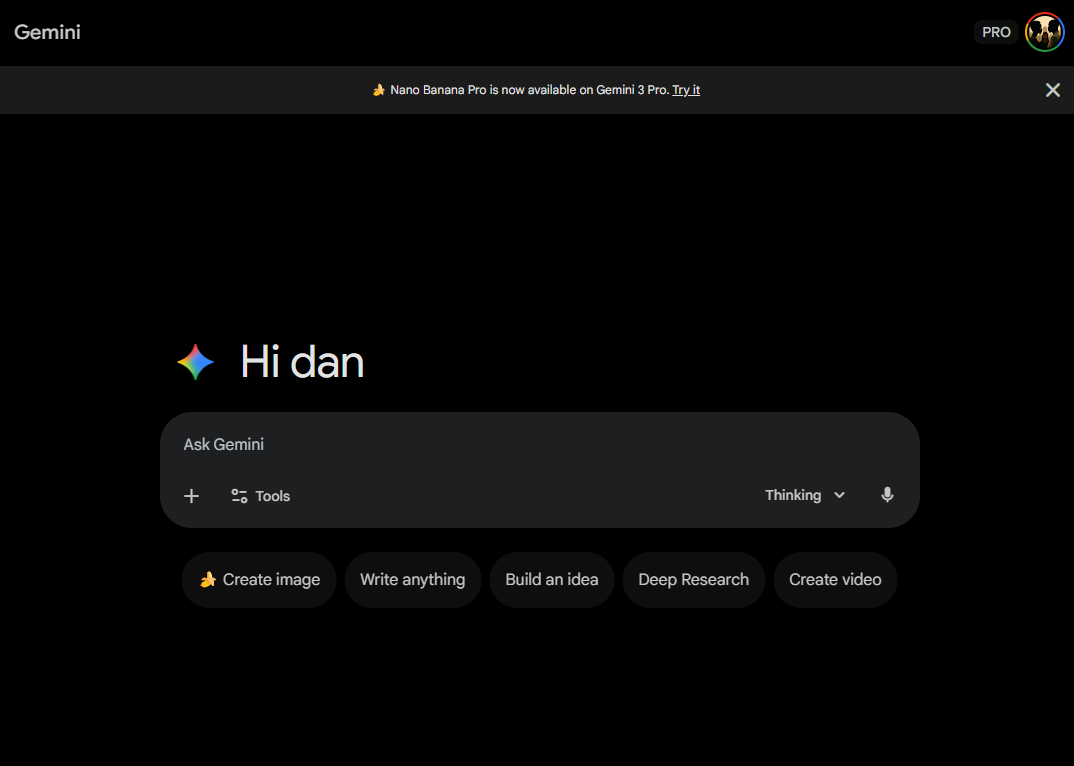
2.1.2 Google AI Studio & Vertex AI (开发者首选),
对于需要 API 接入、批量生成或精细化参数控制的用户,这是核心阵地,以下两者均不包含在会员权益中要绑定银行卡扣费,是按照API调用计算账单。
-
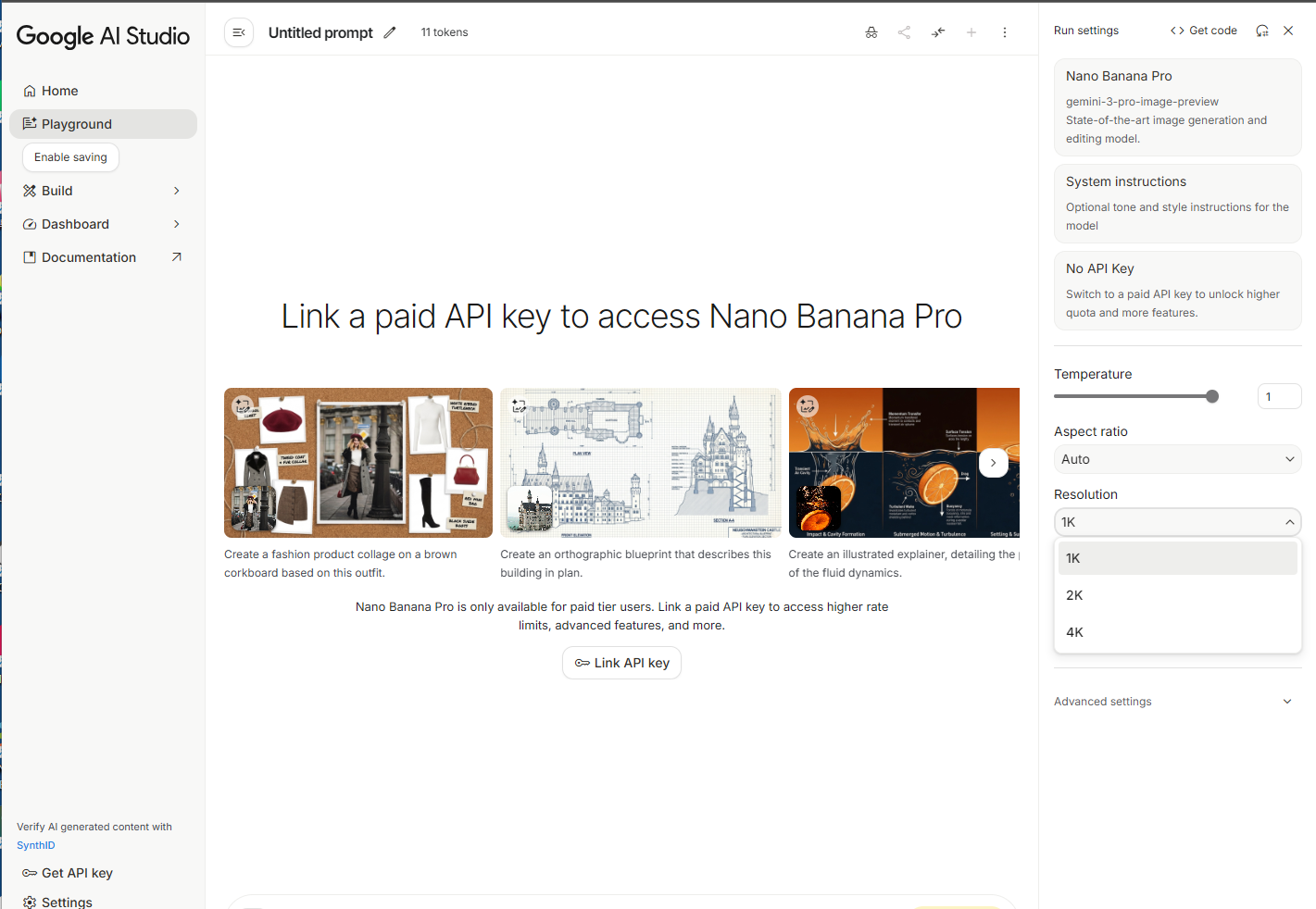
Google AI Studio:这是一个面向开发者的可视化沙盒。你可以在这里测试 Prompt,调整 Safety Filter(安全过滤器等级),设置 Seed(随机种子)以复现结果,并一键导出 Python 或 cURL 代码。它是学习 Nano Banana Pro 参数逻辑的最佳教室。
-
Vertex AI (Google Cloud) :面向企业级部署。通过 Google Cloud 的 Vertex AI Model Garden,企业可以申请高并发的 API 配额,并享受企业级的数据隐私保护(SLA)。Vertex AI 支持将 Gemini 3 Pro Image 集成到企业内部的 ERP、CMS 或营销自动化系统中。
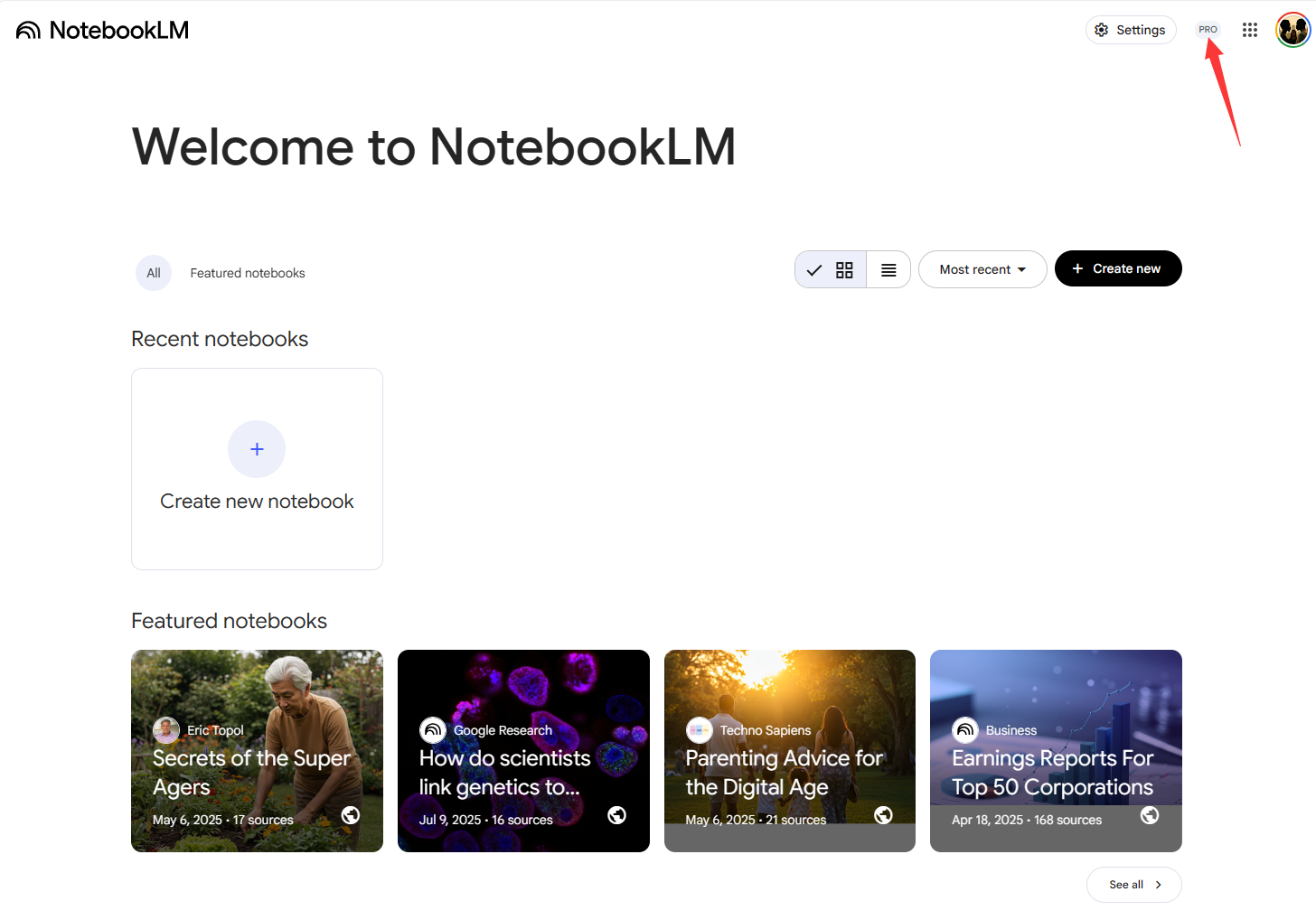
2.1.3 Google Workspace 深度集成
Google 正在将 Nano Banana Pro 的能力内嵌到办公套件中。包含在会员权益中。
- Google Slides:用户可以直接在幻灯片侧边栏描述需求,生成配图。
- NotebookLM:这是一个基于 RAG(检索增强生成)的笔记工具。现在,它不仅能总结文档,还能调用 Nano Banana Pro 为你的笔记自动生成图表、插画或思维导图,极大地提升了信息可视化的效率。
2.2 创意软件集成:设计师的福音
2.2.1 Adobe Firefly & Photoshop
这是一个改变行业格局的合作。Adobe 并未固守自家的 Firefly 模型,而是开放生态,将 Google 的 Gemini 3 Pro Image (Nano Banana Pro) 引入了 Creative Cloud。
- Adobe Firefly Web:在 Firefly 的网页端,“文生图”模块的下拉菜单中新增了 "Gemini 3 (Nano Banana Pro)" 选项。这意味着设计师可以在熟悉的 Adobe 界面中,利用 Google 的模型生成具有极高写实感和精准文字的素材。
- Photoshop Generative Fill:在 PS 的“创成式填充”功能中,用户可以选择底层模型。当需要生成极具真实感的背景扩展或复杂的物体替换时,切换到 Nano Banana Pro 往往能获得比默认模型更好的光影匹配度。Adobe 为 Pro 用户提供了几乎无限的生成次数(在推广期内),这大大降低了试错成本。
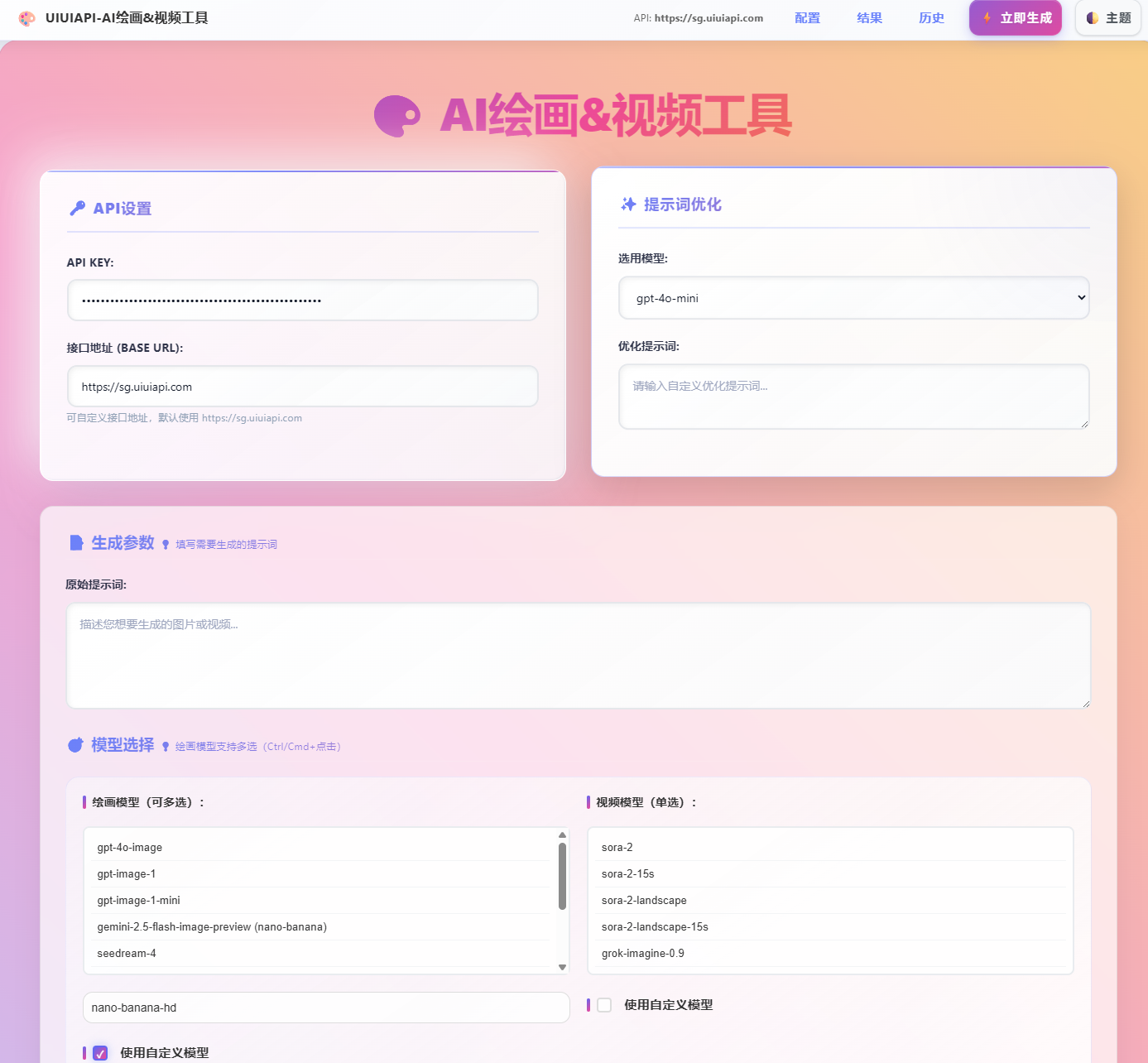
2.3 第三方聚合平台 API 服务商uiuiAPI
对于不希望绑定单一生态,或者寻求更灵活计费方式的开发者,第三方平台提供了便捷的“跳板”。
UIUIAPI:UIUIAPI旗下的 AI 聚合平台已上线 "Nano-Banana-Pro" 模型。用户可以使用UIUIAPI的KEY调用该模型。这非常适合需要同时对比 Claude 3.5 Sonnet、GPT-4o 和 Nano Banana Pro 效果的重度玩家,所有模型都在一个聊天窗口中切换,极度便捷。
第三章:🍌 Nano Banana Pro 怎么用?—— 提示词工程 (Prompt Engineering) 深度实战
掌握了“在哪里用”,更关键的是“怎么用好”。由于 Nano Banana Pro 是一个“讲逻辑”的模型,传统的“标签堆砌法”(Tag Soup,如 masterpiece, best quality, 4k, dog)在这里往往效果不佳。你需要像导演给摄影师写脚本一样,编写结构化的 Prompt。

3.1 核心 Prompt 结构方法论
一个高质量的 Nano Banana Pro 提示词应包含以下五个核心模块,建议按顺序排列:
| 模块 | 说明 | 示例 |
|---|---|---|
| 1. 主体 (Subject) | 核心对象及其详细特征,包括材质、颜色、状态。 | "一个赛博朋克风格的机器人咖啡师,外壳为哑光黑色磨砂金属,眼睛发出温暖的橙色光芒。" |
| 2. 环境 (Context) | 具体的空间描述、时间、氛围。 | "背景是繁忙的东京涉谷街头,雨夜,霓虹灯招牌倒映在湿润的柏油路面上,远处有模糊的行人。" |
| 3. 构图 (Camera) | 镜头语言、视角、景深。 | "低角度仰拍(Low angle shot),使用 35mm 广角镜头,景深突出主体,背景虚化。" |
| 4. 风格 (Style) | 艺术风格、渲染引擎、媒介。 | "电影感概念艺术(Cinematic Concept Art),Unreal Engine 5 渲染,高对比度,赛博朋克美学。" |
| 5. 指令 (Instruction) | 特殊要求,如文字内容、逻辑约束。 | "在画面左上角的灯箱上清晰地写着 'COFFEE 2077' 字样,字体为发光的蓝色无衬线体。" |
3.2 实战场景一:精准文本渲染与海报设计 (Typography & Graphic Design)
Nano Banana Pro 是目前市面上制作带字海报的最强工具。它不仅能拼对单词,还能理解排版布局。
案例目标:设计一张复古风格的火星旅游海报。
Prompt:
"A vintage travel poster for 'Mars'. The text 'VISIT MARS' is written in bold, retro-futuristic red font at the top center. Below the text, a family of astronauts in white suits looks out at a vast red canyon landscape. The text 'The Future Awaits' is written in smaller white sans-serif font at the very bottom. The image has a screen print texture style with halftone patterns."
解析:
- 文字包裹:使用双引号
'VISIT MARS'明确文字内容。 - 方位指令:明确指出
top center(顶部居中)和very bottom(最底部),模型会严格执行这些空间约束。 - 风格融合:请求
screen print texture(丝网印刷纹理)和halftone patterns(半调网点),模型会将文字与这种复古质感完美融合,而不是简单地“贴”上去。
3.3 实战场景二:角色一致性锁定 (Identity Locking)
这是漫画创作、IP 运营和电商模特生成的刚需。Nano Banana Pro 支持多参考图输入,这是实现一致性的关键。
操作流程:
- 生成基准图:首先生成一张满意的角色图(例如一个穿着黄色雨衣的小女孩),保存下来。
- 上传参考:在支持图片输入的界面(如 Google AI Studio 或 Firefly),上传该基准图。
- Prompt 锁定:在提示词中必须显式加入一致性指令。
- Prompt: "Keep the character's facial features, hair style, and yellow raincoat exactly the same as the reference image. The character is now sitting in a futuristic flying car. Wide shot, dynamic lighting."
- 进阶技巧:使用 Character Sheet(角色设定图)。先生成一张包含“正视图、侧视图、背视图”的三视图,然后将这张图作为参考输入,AI 对角色三维结构的理解会呈指数级提升 34。
3.4 实战场景三:3D 漫改与手办风格 (3D Caricature & Figurines)
这是让 Nano Banana Pro 爆火的“看家本领”。它生成的 3D 角色具有极强的皮克斯(Pixar)或泡泡玛特(Pop Mart)质感 35。
Prompt 模板:
"A highly stylised 3D caricature of, with an oversized head, expressive facial features, and playful exaggeration. Rendered in a smooth, polished style with clean materials and soft ambient lighting. Minimal background to emphasize the character's charm and presence. 4K resolution, clay material finish."
技巧:
- 关键词
oversized head(大头)和playful exaggeration(俏皮夸张)是触发卡通风格的关键。 clay material finish(黏土材质)或blind box style(盲盒风格)能增强手办的质感。
3.5 实战场景四:逻辑推理与数学图表
利用 Gemini 的推理能力,你可以让它生成包含正确逻辑的图像,甚至是解决数学题的步骤图 9。
Prompt:
"Solve the equation log_{x^2+1}(x^4-1)=2 on a white board. Show the steps clearly written in black marker. The handwriting should be neat and legible."
解析:模型不会把这当成简单的画图,而是先调用数学引擎解题,然后将解题步骤转化为图像像素。这在教育课件制作中具有巨大潜力。
第四章:开发者进阶 —— Python SDK 与 API 集成指南
对于希望将 Nano Banana Pro 能力集成到自己产品中的开发者,本章将提供基于 Google Vertex AI 和 UIUIAPI 的深度开发教程。我们将探讨如何处理鉴权、参数配置以及错误处理。
4.1 成本分析:企业级应用算得过账吗?
在接入 API 之前,必须了解其计费模型。Nano Banana Pro 的定价反映了其高端定位,但相比自行训练模型仍具有极高的性价比。
| 计费项 | Google Vertex AI 参考价 | uiuiAPI 参考价 | 说明 |
|---|---|---|---|
| 标准生成 (1K/2K) | ~$0.134 / 张 | ~$0.087 / 张 | 包含推理与生成成本,UIUIAPI 略贵但集成更简单。 |
| 高清生成 (4K) | ~$0.24 / 张 | ~$0.105 - $0.787 / 张 | 4K 分辨率是 Nano Banana Pro 的独家优势,适合打印级输出。 |
| 图像输入 (Vision) | ~$0.0011 / 张 | 包含在请求中 | 上传参考图的费用极低,几乎可以忽略不计。 |
| 推理 Token | ~$12.00 / 1M Tokens | 通常打包在图费中 | 部分平台可能将 Gemini 的“思考过程”Token 单独计费。 |
开发者建议:对于非实时要求的批量任务(如夜间批量生成电商图),建议使用 Batch Mode(批处理模式),通常可以获得 50% 的价格折扣。
4.2 基于 UIUIAPI 的极速接入 (Python SDK)
UIUIAPI 提供了封装极佳的 Python 客户端,适合初创团队快速验证产品原型(MVP)。
环境准备:
Bash
pip install fal-client
export UIUIAPI_KEY="your_api_key_here"代码实战:生成一张带文本的 4K 电影海报
Python
import fal_client
import os
# 确保 API Key 已设置
if not os.environ.get("UIUIAPI_KEY"):
raise ValueError("UIUIAPI_KEY environment variable not set")
def generate_poster():
print("正在提交任务至 Nano Banana Pro (uiuiAPI)...")
# 提交任务
# fal-ai/nano-banana-pro 是模型端点
handler = fal_client.submit(
"fal-ai/nano-banana-pro",
arguments={
"prompt": "A cinematic movie poster for a sci-fi film titled 'THE LAST SIGNAL'. Detailed spaceship in a nebula background. Text title in metallic silver font at the bottom.",
"image_size": "4K", # 显式请求 4K 分辨率,这是 Pro 版的特性
"aspect_ratio": "2:3", # 电影海报常用比例
"num_images": 1,
"safety_filter": "block_none", # 开发测试时可适当放宽,生产环境建议开启
"sync_mode": True # 同步等待结果,生产环境建议使用 Webhook 异步回调
}
)
# 获取结果
result = handler.get()
if result and 'images' in result:
image_url = result['images']['url']
print(f"生成成功!图片 URL: {image_url}")
return image_url
else:
print("生成失败或未返回图片。")
return None
if __name__ == "__main__":
generate_poster()代码解析:
image_size="4K":这是调用 Pro 版本的关键参数。大多数其他模型仅支持 1024x1024。safety_filter:Google 的安全过滤器非常严格。在生成某些艺术人体或战斗场景时,可能需要调整此参数以避免误杀 26。
4.3 基于 Google Vertex AI 的深度集成
对于需要深度集成到 Google Cloud 生态(如结合 BigQuery 数据源)的企业,Vertex AI 是唯一选择。
环境准备:
Bash
pip install --upgrade google-genai
gcloud auth login
gcloud config set project YOUR_PROJECT_ID代码实战:多模态图像编辑(图生图 + 文本指令)
Python
from google import genai
from google.genai import types
from PIL import Image
import io
import os
# 初始化客户端
# 注意:Gemini 3 Pro Image 目前在部分区域(如 us-central1)可用
client = genai.Client(vertexai=True, location="us-central1")
def edit_image_workflow(original_image_path, edit_instruction):
print(f"正在加载原图: {original_image_path}")
# 读取原始图片为字节流
with open(original_image_path, "rb") as f:
image_bytes = f.read()
# 构建输入对象
input_image = types.Image(image_bytes=image_bytes)
print(f"发送编辑指令: {edit_instruction}")
try:
# 调用 generate_content 接口
# model="gemini-3-pro-image-preview" 是当前的预览版 ID
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=[
input_image, # 输入图片
edit_instruction # 输入文本指令,例如 "Make it look like winter"
],
config=types.GenerateContentConfig(
response_modalities=["IMAGE"], # 明确指定返回类型为图片
safety_settings=
)
)
# 解析并保存结果
for i, part in enumerate(response.parts):
if part.inline_data:
img = Image.open(io.BytesIO(part.inline_data.data))
output_filename = f"edited_result_{i}.png"
img.save(output_filename)
print(f"编辑完成,已保存为 {output_filename}")
except Exception as e:
print(f"API 调用发生错误: {str(e)}")
# 使用示例
# edit_image_workflow("park.jpg", "Change the season to winter, add snow on the trees and ground")技术洞察:
Vertex AI 的 SDK 允许混合输入(Interleaved Input)。这意味着你可以像构建一个 list 一样,把 [文本, 图片, 文本, 图片] 串联起来发给模型。这种能力使得“基于多张参考图的复杂编辑”成为可能,这是单一的 Text-to-Image API 无法做到的。
第五章:竞品对决 —— Nano Banana Pro vs. Midjourney vs. Flux.2
在 2025 年的 AI 绘图战场,没有绝对的“最强”,只有“最适合”。以下是基于大量实测的深度横向对比。
5.1 详细维度对比表
| 维度 | Nano Banana Pro (Gemini 3) | Midjourney V6 | Flux.2 Pro | DALL-E 3 |
|---|---|---|---|---|
| 核心优势 | 逻辑推理 + 精准文本 | 艺术审美 + 社区氛围 | 开源可控 + 微调生态 | 对话便捷 + 语义理解 |
| 文本渲染 | ⭐⭐⭐⭐⭐ (目前最强,支持排版) | ⭐⭐⭐ (能生成单词,长句易错) | ⭐⭐⭐⭐ (Text 变体优秀,排版稍弱) | ⭐⭐⭐⭐ (准确度尚可,美感不足) |
| 逻辑遵循 | ⭐⭐⭐⭐⭐ (能理解“A在B左边”) | ⭐⭐⭐ (强于艺术,弱于逻辑) | ⭐⭐⭐⭐ (逻辑性较好) | ⭐⭐⭐⭐ (GPT-4 加持,逻辑不错) |
| 画质/分辨率 | 原生 4K | 需 Upscale,原生较低 | 原生高分 | 1024x1024 固定 |
| 角色一致性 | ⭐⭐⭐⭐⭐ (14图上下文学习) | ⭐⭐⭐ (--cref 可用但不可控) | ⭐⭐⭐⭐ (LoRA 微调强大) | ⭐⭐ (较难控制) |
| 上手难度 | ⭐⭐⭐ (需掌握 Prompt 结构) | ⭐⭐ (Discord 操作繁琐) | ⭐⭐⭐⭐⭐ (需本地部署或 API) | ⭐ (对话即可) |
| 适用人群 | 开发者、设计师、营销人员 | 艺术家、插画师、创意总监 | 极客、私有化部署企业 | 普通大众、办公文员 |
5.2 深度选型建议
- 选择 Midjourney 的理由:如果你追求的是“不确定性带来的惊喜”。Midjourney 的默认模型带有极强的艺术滤镜,往往能把普通的 Prompt 渲染得极具大片感。如果你需要灵感爆发,或者制作纯艺术插画,MJ 依然是王者。
- 选择 Nano Banana Pro 的理由:如果你追求的是“确定性带来的效率”。在商业项目中,甲方要求“左边放 Logo,右边放产品,背景要是公司的主题色蓝”,这种硬性约束 Midjourney 往往会为了构图美感而忽略,而 Nano Banana Pro 会严格执行。它是工程化应用(Engineering Application)的首选。
- 选择 Flux.2 的理由:如果你需要“完全的数据隐私”或“极致的微调”。Flux 是开源模型,你可以将其部署在公司内部的 GPU 服务器上,训练自己产品的专属 LoRA。但对于缺乏技术运维团队的企业,Flux 的部署成本较高。
第六章:局限性与避坑指南 (Troubleshooting)
尽管 Nano Banana Pro 表现强劲,但在实际使用中仍存在一些已知的“雷区”。作为专业用户,必须了解如何规避这些问题。
6.1 “塑料感”皮肤问题 (The Plastic Skin Issue)
现象:在生成高写真人像时,皮肤质感有时会显得过于光滑、完美,呈现出一种“蜡像”或“塑料”质感,缺乏真实皮肤的微小瑕疵和毛孔。这是因为模型为了追求“高质量”,倾向于过度降噪和磨皮。
解决方案:
- Prompt 负向优化:不要使用
perfect skin,smooth,3d render等词汇用于真人照片。 - Prompt 正向增强:必须显式加入增加质感的关键词。建议使用的词汇组合:
detailed skin texture(详细皮肤纹理),visible pores(可见毛孔),slight imperfections(轻微瑕疵),raw photography(生图感),unretouched(未修图)。 - 示例:"Portrait of an elderly man, raw photography, high texture skin, visible pores, natural lighting, shot on 85mm lens."
6.2 安全过滤器的“幻觉” (Safety Filter Refusals)
现象:模型拒绝生成某些看起来完全无害的内容,或者生成结果被完全屏蔽。这是因为 Google 的安全策略(Trust & Safety)极为严格,有时会出现误判(False Positives)。
解决方案:
- API 设置:在调用 Vertex AI 或 UIUIAPI 时,尝试将
safety_settings中的阈值设置为BLOCK_ONLY_HIGH甚至BLOCK_NONE(如果你的账号权限允许)。 - Prompt 规避:避免使用可能触发敏感词的描述。例如,如果“战斗”(Fight)被屏蔽,尝试用“动作场景”(Action scene)或“动态姿势”(Dynamic pose)替代。
- 分步生成:如果一次性生成的复杂场景被拒,尝试将其拆解。先生成背景,再通过 In-painting(重绘)添加人物,逐步绕过模型的综合判定逻辑。
6.3 每日配额与并发限制
现象:免费用户在 Gemini Advanced 中经常遇到 "Limit Exceeded"(配额超限)的提示,或者被强制降级到 Flash 模型。
策略:
- 错峰使用:尽量避开美国西海岸的白天时间(即亚洲的深夜)。
- 切换 API:对于生产环境,强烈建议使用 API 模式。虽然需要付费,但能保证 SLA(服务等级协议)和稳定性。

第七章:界智通(jieAGI)内容总结结论 —— AI 绘图的“理性”时代已来
Nano Banana Pro (Gemini 3 Pro Image) 的出现,绝不仅仅是多了一个画图工具那么简单。它标志着 AI 图像生成从“感性抽卡”迈向了“理性构建”的新阶段。
过去,我们使用 Midjourney 像是在玩“盲盒”,期待 AI 给我们惊喜;现在,使用 Nano Banana Pro 像是在操作精密仪器,我们输入明确的指令,获得精确的结果。它不再是一个单纯的玩具,而是一个能够理解复杂逻辑、遵循严格规范、并能融入 Python 自动化工作流的生产力组件。
对于个人创作者,我建议充分利用其在 Adobe Firefly 中的集成,将 AI 生成与传统 PS 修图无缝结合,提升设计效率。
对于开发者,其强大的 API 和对 4K 分辨率、文本渲染的原生支持,使其成为开发自动化设计工具(如自动生成电商海报、动态新闻配图、个性化贺卡应用)的最佳后端模型。
随着未来 Gemini 模型的持续迭代,我们可以预见,图像生成将进一步与多模态代理(Agents)融合——AI 不仅能画图,还能自己上网查资料、核对数据,然后画出一张数据准确、排版精美的统计图表。这正是 Nano Banana Pro 为我们开启的未来图景。
版权信息: 本文由界智通(jieagi)团队编写,图片、文本保留所有权利。未经授权,不得转载或用于商业用途。
本文发布于2025年12月02日00:02,已经过了201天,若内容或图片失效,请留言反馈 转载请注明出处: 界智通
本文的链接地址: https://www.jieagi.com/aizixun/100.html
-

GPT-5-Codex保姆级教程:获取OpenAI APIKey与安装 Codex CLI使用教程全面指南
2025/09/17
-
2025最新:Claude Pro 与 Max 区别详解与订阅指南
2025/08/26
-
Gemini 报错 "Something went wrong" 终极解决指南
2025/11/27
-
Cursor权威指南:从注册入门到精通AI驱动编程工作流(含国内注册与验证说明)
2025/08/27
-
2025最新保姆级教程:如何获取Claude API Key?从注册到Python调用,一篇搞定!
还在为如何申请 Claude API Key 而头秃吗?随着 Claude 4.5 Sonnet 在编程能力上的强势崛起,越来越多的开发者开始转向 Anthropic 的阵营。本文将通过“保姆级”的图文实操,带你一步步解决账号注册、手机号验证、API Key 获取及额度充值等难题,并附带 Python 极简调用示例。无论你是想接入 LangChain 还是自己在这个强大的模型上跑 Demo,这篇文章都能帮你避开 99% 的坑!
2025/11/15
-
【实测有效】Gemini 3 / Google Antigravity 授权登录无反应、无权限?全平台解决办法汇总指南
2025/11/22
-
[2025最新] ChatGPT Plus 订阅终极指南:四种充值方案与深度解析:为什么它值$20?
2025/11/13
-
Grok-4.1 深度拆解:马斯克的“叛逆”AI怎么接入?xAI Grok API Key 获取及开发攻略
想要体验马斯克旗下xAI的Grok大模型?本文详细拆解 Grok API Key 获取的全流程,从账号登录、控制台设置到API Key生成,并附带完整的Python调用代码示例。解决开发者在申请过程中遇到的支付、权限等常见问题,助你快速将“叛逆”的Grok集成到自己的应用中。
2025/11/18
-
Google AI Pro 有什么功能?Google AI Pro 生态系统深度报告以及订阅会员权益功能全面分析
2025/11/29
-
OpenAI GPT-5 深度解析:API Key定价与ChatGPT(Free, Plus, Pro)用户的区别
2025/08/08





![[2025最新] ChatGPT Plus 订阅终极指南:四种充值方案与深度解析:为什么它值$20?](https://www.jieagi.com/content/uploadfile/202511/249b1763003156.png)




暂无评论





太好看了,快点更新!
国内开发者玩转Claude:最新Claude 4模型解析与API Key获取攻略
这是系统生成的演示评论
国内开发者玩转Claude:最新Claude 4模型解析与API Key获取攻略