
 界智通
界智通 【OpenAI】TTS文本转语音:获取OpenAI API Key与Python脚本安全高效的文本转语音(TTS)实践
 jieagi_Pan
jieagi_Pan 下面是一份较全面、实用的 OpenAI 文本转语音(TTS)功能介绍与上手指南,涵盖模型选择、声音与语言、输出格式、调用方式、流式播放、长文本分段、质量控制技巧、费用与限额、常见问题等。

一、功能概览
- 作用:将输入的文字即时合成自然语音,可用于旁白、语音播报、对话型产品的发声等。
- 特点:延迟低、可多语言、提供多种预设音色(voices),可输出多种音频格式,支持流式播放。
- 典型延迟:短句通常在数百毫秒到约 1–2 秒内即可得到可播放的音频;与网络状况、模型与格式有关。
二、可用模型与差异
- gpt-4o-mini-tts(推荐默认):速度快、性价比高,适合绝大多数实时与批量场景。
- tts-1:早期通用 TTS 模型,质量与速度均衡。
- tts-1-hd:更高音质版本,适合对音频保真度要求更高、对延迟不太敏感的长内容旁白。
提示:若追求最低延迟与成本,优先 gpt-4o-mini-tts;若追求极致音质,可尝试 tts-1-hd。老的 tts-1/tts-1-hd 仍可用,但官方通常建议新项目优先采用 gpt-4o-mini-tts。
三、声音与语言
- 预设声音(voices):提供多款风格不同的声音,常见示例有 alloy、verse 等。不同声音在语气、音色、语速上存在差异。
- 语言支持:多语言合成(英文最佳),中文、日语、西班牙语等也可用;不同声音在非英语场景中的自然度可能不同,建议对目标语言逐一试听挑选。
- 注意:目前官方未明确支持完整 SSML 控制(如精细的停顿、语速、音高标签)。但标点、段落分割、舞台指令式文字(如“[停顿2秒]”)常能对韵律产生一定影响。
四、输出格式与采样率
- 常见格式:mp3(体积小,通用)、wav(无损/PCM,适合后期处理)、ogg/opus(体积更小、延迟低,适合流式)。
- 采样率:由格式和服务端默认策略决定;如需特定采样率,可在客户端做重采样处理(ffmpeg、sox 或 WebAudio)。
五、获取与安全使用 API Key(两种连通方式)
好的,这段文案的目标是引导用户选择“方式B”,同时显得客观、有说服力。我们可以从标题、结构、措辞和用户心理等角度进行优化。
获取 OpenAI tts-1 API KEY?看这两种方式就够了
-
方案A:官方渠道
- 特点: 流程繁琐,对网络环境有特殊要求,新手容易在注册和使用中遇到障碍。
- 适合: 熟悉海外服务注册流程,且网络条件好的资深用户。
-
方案B:国内加速 (为开发者便捷调用)
- 特点: 借助专业中转服务 (如
uiuiapi.com),连接稳定、速度快、开通简单,即刻上手。 - 适合: 追求稳定高效,希望快速开始使用的所有开发者,也是众多资深用户的选择。
- 特点: 借助专业中转服务 (如

如何调用(概览)
在现代应用开发中,调用第三方 API 是一项基本技能。我们常常从一个简单的 curl 命令开始测试,但要将其转化为生产级别的代码,则需要考虑安全性、可维护性和健壮性。
本教程将以一个文本转语音(TTS)API 为例,带您一步步将一个 curl 命令,升级为一个安全、高效且专业的 Python 脚本。
起点:一个简单的 curl 命令
假设我们有一个 TTS 服务的 curl 命令,它的作用是发送一段文本,并接收一个 mp3 音频文件作为响应。
curl https://sg.uiuiapi.com/v1/audio/speech \
-H "Authorization: Bearer $YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "tts-1",
"input": "你好,世界!",
"voice": "alloy"
}' \
--output speech.mp3这个命令虽然能用,但存在几个问题:
- 密钥暴露:API 密钥直接在命令行中使用,可能保存在历史记录中。
- 不易集成:难以在复杂的程序中复用。
- 缺乏错误处理:如果请求失败,我们只能得到一个简单的 HTTP 错误,没有程序化的处理逻辑。
第一步:将 curl 转换为 Python 代码
为了在程序中调用 API,我们使用 Python 中广受欢迎的 requests 库。它是处理 HTTP 请求的黄金标准。如果尚未安装,请先安装它:
pip install requests接下来,我们可以将 curl 命令直接翻译成 Python 代码:
import requests
# API 的 URL 地址
url = "https://sg.uiuiapi.com/v1/audio/speech"
# 请求头,对应 curl 的 -H 参数
headers = {
"Authorization": "Bearer sk-xxxxxxxxxxxx", # 注意:密钥暂时硬编码
"Content-Type": "application/json",
}
# 请求数据,对应 curl 的 -d 参数
data = {
"model": "tts-1",
"input": "你好,世界!",
"voice": "alloy"
}
# 发送 POST 请求
response = requests.post(url, headers=headers, json=data)
# 将接收到的音频内容写入文件
if response.status_code == 200:
with open("speech.mp3", 'wb') as f:
f.write(response.content)
print("音频文件已成功保存!")
else:
print(f"请求失败,状态码: {response.status_code}")
print(f"错误信息: {response.text}")
这段代码实现了与 curl 相同的功能,但我们很快就发现一个严重的问题:API 密钥被硬编码在了代码中。这是一个巨大的安全隐患。
第二步:使用 .env 文件安全管理 API 密钥
专业的开发实践严禁将密钥、密码等敏感信息直接写入代码。最佳实践是使用环境变量来管理它们。dotenv 文件是本地开发中最流行的方式。
1. 安装 python-dotenv 库
pip install python-dotenv2. 创建 .env 文件
在您的项目根目录下(与 Python 脚本同级),创建一个名为 .env 的文件。在里面定义您的密钥。我们使用 UIUIAPI_API_KEY 这个清晰的变量名。
.env 文件内容:
# 这是环境变量文件,用于存放敏感信息
# UIUIAPI_API_KEY,输入你在uiuiapi.com或者OpenAI官方的KEY
UIUIAPI_API_KEY="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"3. (至关重要)将 .env 添加到 .gitignore
为了防止将含有密钥的 .env 文件提交到代码仓库(如 GitHub),请务必在 .gitignore 文件中添加一行:
.env4. 在 Python 中加载并使用密钥
现在,我们修改 Python 脚本,使用 dotenv 库来加载 .env 文件中的变量。
import os
import requests
from dotenv import load_dotenv
# 加载 .env 文件中的环境变量
load_dotenv()
# 从环境中安全地获取 API 密钥
api_key = os.environ.get("UIUIAPI_API_KEY")
# 如果未找到密钥,则立即报错退出
if not api_key:
raise ValueError("未找到 API 密钥。请确保在 .env 文件中设置了 'UIUIAPI_API_KEY'")
# ... 后续代码使用 api_key 变量 ...
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
# ...通过这三步,我们成功地将密钥与代码分离,大大提升了应用的安全性。

第三步:参数化与模型选择
一个好的脚本应该是灵活的。TTS API 通常提供多种语音模型供选择。我们可以将输入文本和语音模型作为参数,方便调用。
以 OpenAI 的 TTS 模型为例,它提供了 6 种高质量的声音:
alloy(均衡男声)echo(温暖男声)fable(沉稳男声)onyx(深沉男声)nova(活泼女声)shimmer(专业女声)
我们可以在代码中轻松切换它们:
# 要转换的文本
input_text = "你好,世界!提笔写下这句简单的问候,我带着好奇、敬意与希望。"
# 选择一个声音
selected_voice = "nova"
# 构造请求数据
data = {
"model": "tts-1",
"input": input_text,
"voice": selected_voice
}第四步:构建健壮的错误处理和流式下载
网络请求总是有可能失败。一个生产级的脚本必须能优雅地处理各种错误。同时,对于音频这类可能较大的文件,使用流式下载可以有效防止内存溢出。
我们可以结合 try...except 块和 response.raise_for_status() 来构建一个健壮的请求逻辑。
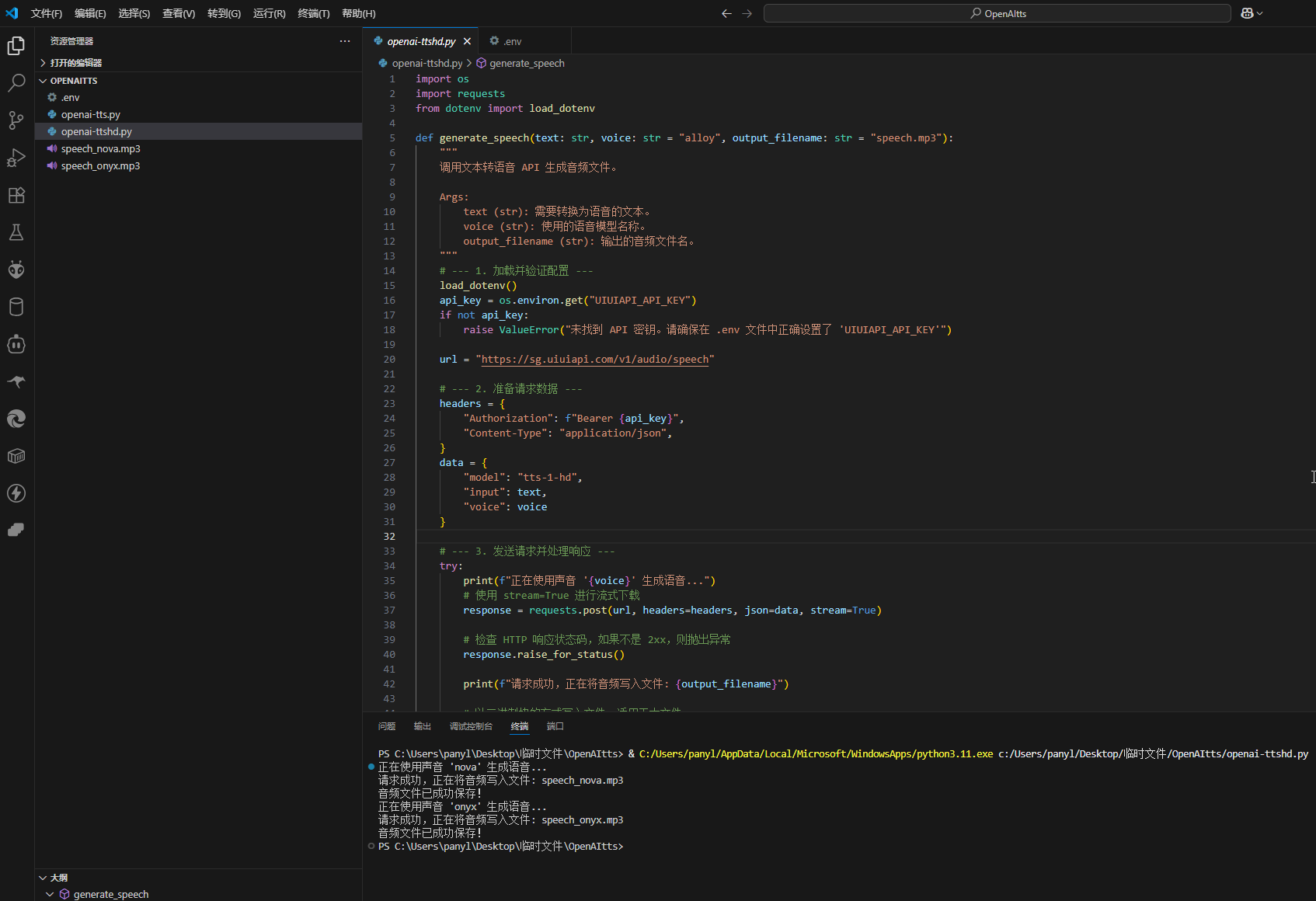
最终版本:专业级的 TTS API 调用脚本
结合以上所有最佳实践,我们得到最终的 Python 脚本。它安全、健壮、灵活且易于维护。
import os
import requests
from dotenv import load_dotenv
def generate_speech(text: str, voice: str = "alloy", output_filename: str = "speech.mp3"):
"""
调用文本转语音 API 生成音频文件。
Args:
text (str): 需要转换为语音的文本。
voice (str): 使用的语音模型名称。
output_filename (str): 输出的音频文件名。
"""
# --- 1. 加载并验证配置 ---
load_dotenv()
api_key = os.environ.get("UIUIAPI_API_KEY")
if not api_key:
raise ValueError("未找到 API 密钥。请确保在 .env 文件中正确设置了 'UIUIAPI_API_KEY'")
url = "https://sg.uiuiapi.com/v1/audio/speech"
# --- 2. 准备请求数据 ---
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
data = {
"model": "tts-1-hd",
"input": text,
"voice": voice
}
# --- 3. 发送请求并处理响应 ---
try:
print(f"正在使用声音 '{voice}' 生成语音...")
# 使用 stream=True 进行流式下载
response = requests.post(url, headers=headers, json=data, stream=True)
# 检查 HTTP 响应状态码,如果不是 2xx,则抛出异常
response.raise_for_status()
print(f"请求成功,正在将音频写入文件: {output_filename}")
# 以二进制块的方式写入文件,适用于大文件
with open(output_filename, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
print(f"音频文件已成功保存!")
except requests.exceptions.HTTPError as e:
# 捕获并打印更详细的 HTTP 错误信息(如 401, 404, 500 等)
print(f"请求失败,HTTP 错误: {e}")
print(f"响应内容: {response.text}")
except requests.exceptions.RequestException as e:
# 捕获网络或连接错误
print(f"请求失败,网络或连接错误: {e}")
except Exception as e:
# 捕获其他未知错误
print(f"发生未知错误: {e}")
if __name__ == '__main__':
# --- 使用示例 ---
long_text = "你好,世界!提笔写下这句简单的问候,我带着好奇、敬意与希望:无论经纬如何交错,我们共享同一片天空与明月。我愿倾听你每个角落的故事,珍视差异,守护脆弱的美好。"
# 使用活泼的女声 'nova'
generate_speech(long_text, voice="nova", output_filename="speech_nova.mp3")
# 使用深沉的男声 'onyx'
generate_speech("欢迎体验我们的文本转语音服务。", voice="onyx", output_filename="speech_onyx.mp3")界智通(jieagi)总结流程:
- 1.创建文件夹例如
openaitts。 - 2.在
openaitts文件夹目录下创建.env文件存放秘钥。 - 3.在
openaitts文件夹目录下Python 脚本的文件。
完成步骤运行你的脚本文件。
我们从一个简单的 curl 命令出发,通过引入 requests 库、使用 .env 文件保护密钥、参数化 API 调用以及构建健壮的错误处理,最终完成了一个专业级的 Python 脚本。
这个过程体现了从“能用”到“好用”的软件工程思维。您可以基于此脚本,进一步将其封装成类,或者构建一个命令行工具(CLI),甚至集成到大型 Web 应用中,为您的项目赋予强大的语音能力。
本文发布于2025年08月24日17:23,已经过了300天,若内容或图片失效,请留言反馈 转载请注明出处: 界智通
本文的链接地址: https://www.jieagi.com/daimashili/62.html
-

OpenAI API Key 获取与 Codex 自定义网关配置实战(附完整代码)
2026/03/31
-
获取OpenAI API Key使用Python 调用Sora2文生视频开发(附代码)
2025/10/20
-
从零到高手:Mac安装Claude Code CLI全攻略,让AI成为你的编程搭档
嘿,兄弟姐妹们!作为一名在代码海洋里摸爬滚打多年的老鸟,我知道你们总在为调试代码、脑洞创意抓狂。想象一下,有个AI助手像忠实伙伴一样,随时帮你生成代码、解释难题——这就是Claude Code CLI的魅力!它能让你的编程效率像火箭一样飙升。今天,我手把手带你安装配置,确保你零门槛上手。走起,别让AI的魔法溜走! 先检查你的“装备”:安装前提 别急着冲,先确...
2025/07/21
-
【保姆级实战】在腾讯云搭建“私有版”NotebookLM:Open Notebook 国内环境深度部署指南
2025/12/19
-
零门槛上手:获取OpenAI API Key用 GPT-5 打造你的私人 PDF 分析机器人( 附!Python代码)
2025/08/27
-
Cursor - AI编程工具接入uiuiAPI聚合平台图文教程
(1) Cursor简要 Cursor 是一类以大语言模型(LLM)为核心、面向开发者的交互式编码 IDE/助理工具。它把自然语言对话、代码理解、即时运行与编辑器/终端集成在一起,帮助开发者更快地阅读、生成、重构、调试代码与编写测试等。 (2) 接入uiuiAPI聚合平台教程 点开Models进行,在APIKeys点开,选择OpenAI APIKey进行配置...
2025/08/18
-
Claude Code 国内最新落地实战:Windows 下保姆级安装指南(2025避坑版)
2025/12/17
-
OpenAI API 实战教程:如何稳定获取结构化 JSON 输出
2025/08/26
-
OpenAI API Python实战教程:如何稳定获取结构化 JSON 输出(简易/复杂 双示例)
2025/08/26
-
精通AI编程工具:Claude Code 命令的高级技巧使用教程,提升您的开发效率~
2025/08/19









暂无评论









太好看了,快点更新!
国内开发者玩转Claude:最新Claude 4模型解析与API Key获取攻略
这是系统生成的演示评论
国内开发者玩转Claude:最新Claude 4模型解析与API Key获取攻略